
AWS Simple Storage Service (S3) is the most popular object storage among many companies. Its demand can be explained by such characteristics as availability and scalability. However, it may be difficult to understand what levels of accessibility, latency, as well as redundancy are required in each unique case. Having zero understanding regarding these details will inevitably lead to overpayment for the owned storage or even mission-critical data loss (in case no backups are made).
This article is prepared to explain what AWS S3 storage is, define what factors affect S3 pricing, as well as discover what classes of S3 storage can be deployed. On top of that, we’ve described steps that can be taken to optimize Amazon S3 storage costs.
What is Amazon S3?
Amazon S3 is object storage created to store, access, and reclaim any amount of data on the internet. As we assume, the main reason why this type of AWS storage is the most commonly used is that it’s scalable, durable, and presented at a reasonable price.
Additionally, S3 offers approximately 100% uptime and unlimited storage, as well as provides the company’s sensitive data protection, according to the security and compliance standards. This type of storage is typically used with websites, mobile applications, data analytics, archive, backup, and so on.
Nevertheless, AWS customers still find it rather challenging to understand S3 pricing. In order to make it clear, AWS S3 storage users should take into account the parameters that can influence its cost.
What factors determine AWS S3 pricing?
There are seven main parameters that influence how much the company will pay for the storage: the region where the data is stored; the volume of stored data; the level of redundancy; the selected class of storage; as well as data requests, transfers, and retrievals.
Let’s consider the specifications of each parameter and explore how exactly it affects Amazon Simple Storage Service price.
1. Storage region
There are 24 different regions where AWS customers can store their data nowadays. As you’ve already guessed, the prices are different for each region where the data can be stored. If you wish to reduce the storage cost, compare all regions’ costs and choose the one that is acceptable for your company in terms of the data storage policy.
Below, there is a sample of the pricing for the Northern California and Ohio regions:

2. Volume of stored data
The volume of data you store in S3 influences its price: the more data is stored in the Standard storage tier, the less you have to pay per GB. Furthermore, Amazon Simple Storage Service has a free tier for the first year of your contract that provides you with 5GB of Standard S3 storage.
Here is the S3 Standard storage pricing for the Ohio region presented by AWS:

3. Redundancy level
AWS assures its customers that the data stored in the S3 storage service is greatly durable. However, unpredictable events may happen. So, to prevent any disaster like potential data loss, Amazon Web Services replicates data stored in the Standard storage tier, the Standard Infrequent Access storage tier, and the Archive storage tier across at least three Availability Zones.
Note that business-critical data replication to another region or within the same region increases costs approximately by 2 times, as you pay for the additional GBs. Moreover, you will pay for the PUT requests, as you add (or put) your data to another S3 bucket.
In order to reduce the costs for S3 storage, you can replicate the most important data to another region and then transfer that data to a cheaper storage class to cut down disaster recovery costs. You can decrease the level of redundancy for the data of another nature.
Additionally, you can view the AWS S3 pricing for replication services in detail here, and then choose the strategy that matches your goals and needs.
4. Class of storage
The Amazon S3 service provides companies with the opportunity to store data in different storage classes (or tiers). It’s recommended to choose the class keeping in mind how often you need to access the data, for how long you need this storage, as well as which level of redundancy and availability you expect.

Here are the S3 classes AWS offers to its customers:
- S3 Intelligent-Tiering for data with fluctuating access patterns (this type of storage implies automatic cost savings);
- S3 Standard for the data that it planned to be frequently accessed;
- S3 Standard-Infrequent Access (S3 Standard-IA), and S3 One Zone-Infrequent Access (S3 One Zone-IA) for the data you want to access less frequently;
- S3 Glacier Instant Retrieval for archive data that you may need to access immediately;
- S3 Glacier Flexible Retrieval (formerly S3 Glacier) for rarely accessed long-term data that you don’t need to access immediately;
- Amazon S3 Glacier Deep Archive (S3 Glacier Deep Archive) for long-term archive and digital preservation with retrieval in hours at the lowest cost storage in the cloud.
Additionally, there is one more class – S3 Outposts that allows users to store S3 data on-premises, in the case when the data residency requirements don’t match one of the presented AWS Regions.
All in all, turning back to the pricing issue, if you plan to access the data frequently, it’s better to place it in the Standard S3 tier instead of the Infrequently Accessed and Archive tiers. Although they are less expensive, they were not created for the repeatedly accessed data. That’s why it costs more for PUT and GET requests and to retrieve data from the Infrequently Accessed and Archive tiers.
There is the Intelligent-Tiering service provided by AWS. It can significantly reduce the management process by automatically transferring data to the most cost-efficient access class – between Standard S3 tier and Standard Infrequent tier, as well as between Archive and Deep Archive.
However, keep in mind, it incurs a charge of $0.0025 per thousand items monitored, so costs can increase rapidly if the service is left without attention.
5. Data requests
S3 costs fluctuate due to the way the data is accessed. Also, the cost depends on the type of request (whether it’s PUT, COPY, SELECT or GET), the number of requests, and the volume of retrieved data.
For instance, 1,000 PUT requests to the S3 Standard tier cost $0.005, while 1,000 GET requests to the same tier cost $0.0004. So, it’s vital to take into consideration how you plan to access your data when you choose a storage class.
6. Data transfers
Data transfer into Amazon S3 is free. However, when you transfer data out from an S3 storage bucket, for instance, to another region, costs are incurred. In this case, the discounts can be applied, too. So, the more data is transferred out, the lower the rate per GB is.
Talking about data transfer out to the internet, the first 1GB/month is free, then the price varies from $0.05 per GB to $0.09 per GB (depending on the volume of the data transferred).
However, outbound data transfers to another region also depend on the distance between regions. So, the cost for regions in North America and Europe is around $0.02 per GB, while outbound data transfer costs for the data stored in the Asia Pacific, South America, Africa, and the Middle East are significantly higher.
It’s worth mentioning that the data transfer out to Amazon CloudFront is always free.
7. Data retrievals
The last but not the least parameter that affects AWS S3 pricing is retrievals of data. Amazon customers can retrieve data from a Standard S3 storage volume for free. However, if your data is placed in an Infrequent or Glacier storage tier, you will be charged for requests and data retrievals.
The volume of retrieved data determines the pricing for data retrieval. Also, the pricing depends on the kind of retrieval from archive storage (expedited or bulk one).
The first 10GB of S3 Glacier retrievals are free, then, the customer is charged per GB fee. Request prices for Glacier data retrieval vary from pennies per 1,000 requests for bulk requests to $10 per 1,000 requests for expedited requests. So, it’s recommended to relocate the data, if you make hundreds and thousands of data retrieval requests monthly.
There are retrieval services offered by AWS that can speed up data retrieval and save money on data transfer costs – S3 Select and Glacier Select. They give users the opportunity to retrieve data subsets, instead of the entire objects.
Optimize Amazon S3 costs with Binadox
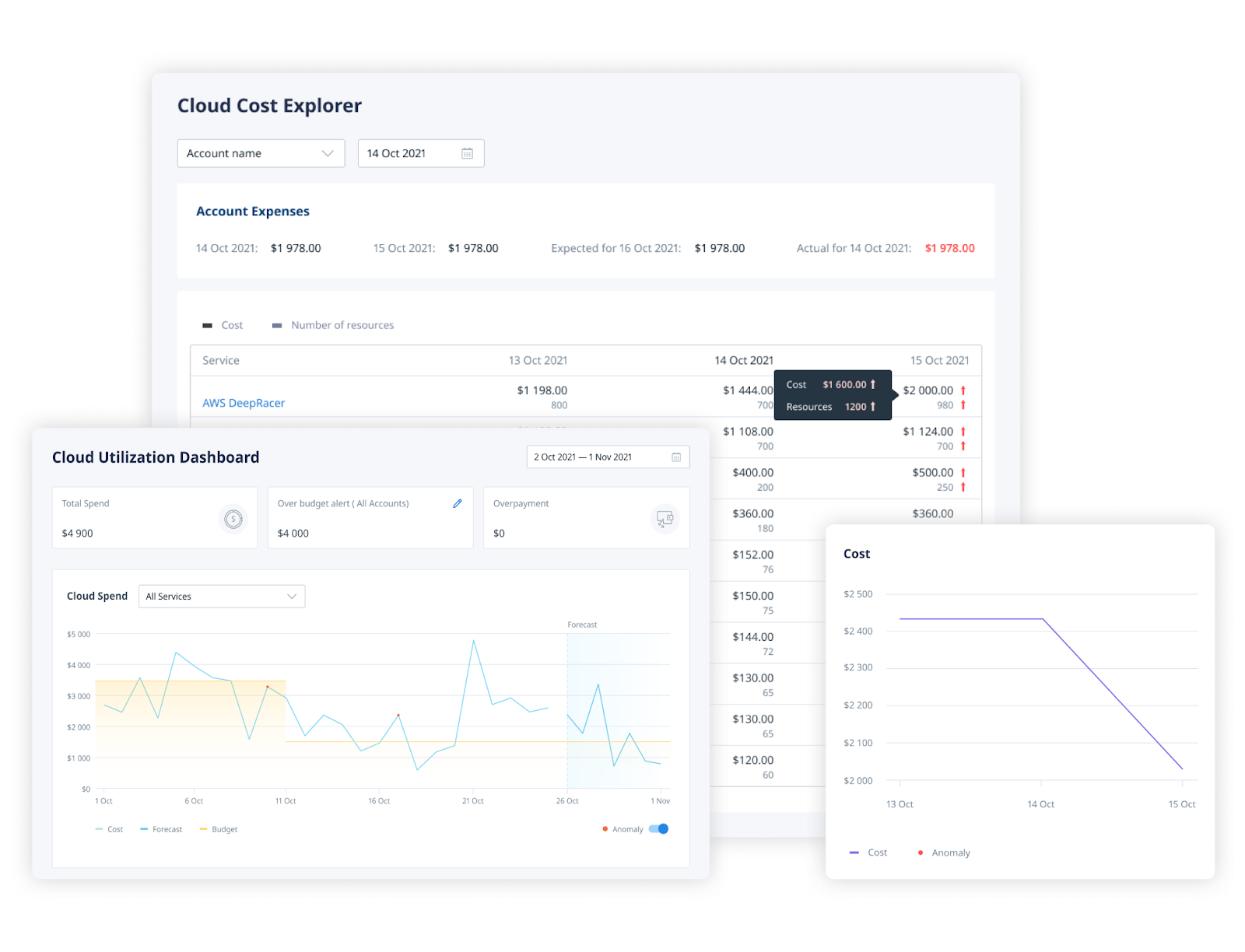
You can manage Amazon S3 storage and optimize its costs with the cloud management solution Binadox. First of all, you can either view all the consumption patterns of the deployed AWS services or examine S3 coYou can manage Amazon S3 storage and optimize its costs with the cloud management solution Binadox. First of all, you can either view all the consumption patterns of the deployed AWS services or examine S3 costs separately. Also, there is a possibility to track the expenditures by region or by service.
Cloud Utilization Dashboard allows Binadox users to monitor the spendings on Amazon S3, view the total spend, set the daily budget, identify the possible overpayment and get the immediate notification if the defined budget threshold is reached. In the long run, the unified dashboard helps companies to analyze the current situation and make more reasonable decisions for the future.
Cost Explorer brings a granular view of your expenditures on AWS Simple Storage Service and a more thorough understanding of your cloud investments allocation.
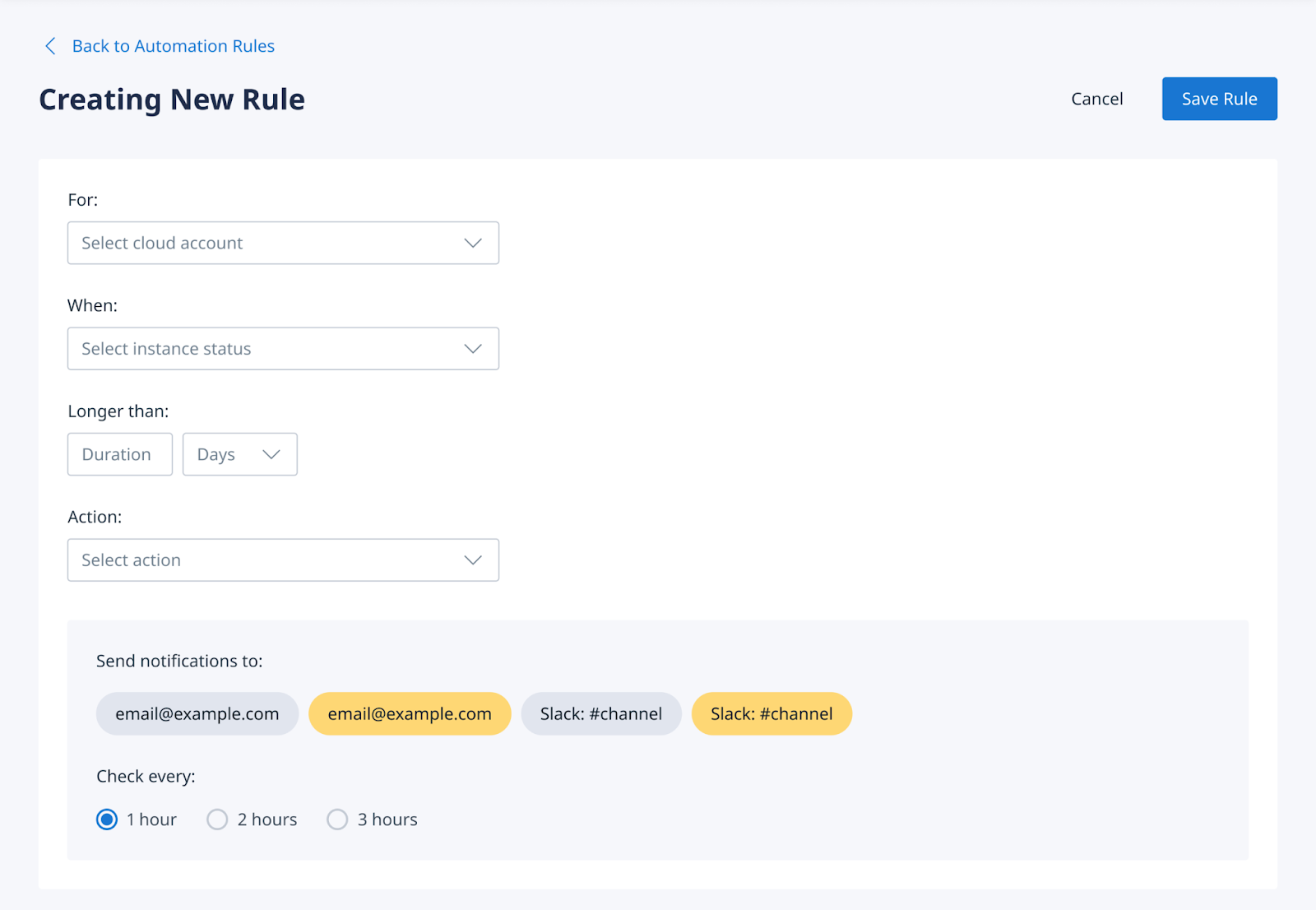
One more relevant issue that affects S3 deployment is security. Binadox has an Automation Rules feature that can help you to create security-related rules and receive alerts when the defined condition is met. It does not only reduce the manual work but also allows you to be aware of any changes ongoing in your cloud infrastructure.
The Advice section informs about all occurring security threats concerning Amazon Simple Storage Service. If Binadox detects any issue, it sends a notification to the connected communication channel, so you’re always up-to-date.
If you want to see how S3 cost optimization works in practice, sign in for a free trial and test all Binadox features. Also, book a demo to understand how the platform works and how Binadox can help your company in particular.