
Modern cloud cost management discussions nearly always reach the same fork in the road: should you wrap workloads into portable containers, orchestrated by Kubernetes/ECS/EKS/AKS, or hand them off to a fully managed Function‑as‑a‑Service layer such as AWS Lambda or Google Cloud Functions? Both promise hands‑off elasticity, but their Total Cost of Ownership (TCO) diverges in ways that only become obvious when the monthly bill lands in your inbox.
1. Quick primer
| Model | What you manage | Core pricing signal |
|---|---|---|
| Containers (CaaS / PaaS) | Image build, runtime, cluster capacity & scaling rules | Provisioned vCPU‑hour / GiB‑hour + egress & storage |
| Serverless (FaaS) | Only function code & memory setting | Executed GB‑seconds + request count |
In short, containers charge for capacity you keep running, whereas serverless charges for the capacity you actually consume. That philosophical difference informs everything else that follows.
One subtle detail often missed in quick comparisons is granularity. Public‑cloud container engines typically meter per‑second to per‑minute. Serverless platforms, on the other hand, bill in ms slices—100 ms on Lambda, 1 ms on Google Cloud Functions (Gen2). When invocations last only 20–50 ms, that billing quantum alone can swing costs by double‑digit percentages.
Another nuance is memory‑CPU coupling. In many FaaS offerings, CPU power scales linearly with the memory knob (e.g., 1 vCPU at 1,792 MB on Lambda). If a workload is compute‑light but memory‑hungry (or vice‑versa), you may overpay. Containers let you decouple those dimensions and squeeze utilisation closer to 70–80 % on both axes.

2. Key cost drivers to watch
- Utilisation pattern
If average CPU load stays below ~20 % over a 24×7 window, you are effectively sponsoring idle silicon. Because serverless traces cost to execution time, it wipes that idle premium. The reverse is true once your p95 utilisation rises: platform overhead and higher per‑unit pricing begin to dominate. - Startup latency & concurrency limits
Cold‑starts force developers to over‑allocate memory as a hedge against timeouts. A 128 MB Node.js function that idles cheaply may balloon to 1 GB once tuned for better latency—multiplying GB‑seconds by eight. - Networking, egress & cross‑AZ chatter
Container clusters usually share a regional VPC, whereas serverless products sometimes impose per‑function NAT gateways or VPC attachments. At scale, those $0.045 per GB egress charges can outpace compute. - Operational overhead (people cost)
Patching worker nodes, resizing node groups, updating sidecars—these tasks materialise as engineering time. Treat a $140k site‑reliability engineer as roughly $70/hour burdened cost; shaving even two hours a week by off‑loading ops can shift your TCO curve.

To make those drivers concrete, imagine a video‑transcoding micro‑service that runs 24/7 at 65 % CPU. On EKS with ARM‑based spot instances you might pay $0.012/vCPU‑hour in us‑east‑1. Move that to Lambda and you incur roughly $0.00001667 per GB‑second. Because each invocation needs 3,008 MB for 90 seconds, a single job consumes 271k GB‑ms—or about $4.5 for 1,000 runs, plus $0.20 per million requests. Multiply that across 60 transcodes an hour and serverless is suddenly 4× the container price.

3. When serverless is the cheaper choice
- Event‑driven peaks – think Black‑Friday image uploads, asynchronous IoT messages, cron‑triggered ETL jobs.
- Prototyping and MVPs where paying “pennies per invocation” is better than reserving nodes you may scrap in two months.
- Global low‑latency presence: a single function can be replicated to edge locations without multi‑cluster governance overhead.
- Compliance scopes: if a given event touches regulated data only sporadically, isolating it in a function can cut audit surface without keeping an entire HIPAA‑hardened cluster warm.
» Pro tip: Before a migration frenzy, run a cloud cost anomaly assessment to validate that traffic is truly spike‑heavy. Our guide on detecting cloud cost anomalies explains which CloudWatch metrics to export and how to visualise them in Binadox.
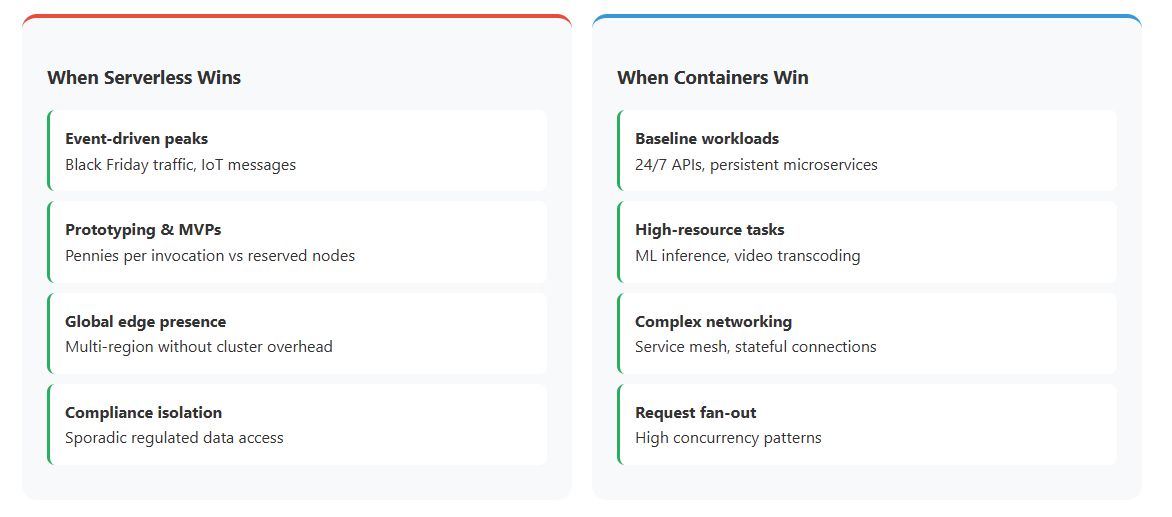
4. Where containers pull ahead
- Baseline workloads – REST APIs, persistent micro‑services, real‑time data pipelines that hum 24/7.
- High‑memory or CPU‑intensive tasks such as ML inference, financial modelling, or video transcoding, where FaaS pricing tiers leapfrog container spot instances.
- Complex networking patterns: service mesh sidecars, stateful connections, GPU reservations, or compliance‑oriented PCI‑DSS segmentation.
- Steep request fan‑out: architectures that fan a single API request into hundreds of downstream calls can hit Lambda’s concurrency ceilings, while a container pod can queue naturally via back‑pressure.
5. Blended strategies & dynamic optimisation
The most sophisticated teams don’t treat serverless and containers as rivals; they orchestrate both within a Cost‑Optimised Cloud Fabric:
- Burst off‑load: keep “always‑on” APIs in EKS, but route S3‑triggered image thumbnails to Lambda for micro‑bursts.
- Job orchestration: Kubernetes CronJobs fire event bridge targets that spin short‑lived functions, achieving 100 ms billing while retaining cluster observability.
- Cost‑aware scheduling: Binadox Rightsizing and Automation Rules shrink container nodes overnight and flag functions that cross historical cost baselines.
In a recent e‑commerce case study, this hybrid approach shaved 37 % of monthly compute spend—20 % from aggressive node down‑scaling and 17 % from eliminating idle functions.
6. Feature spotlight: Binadox tooling for Cloud & SaaS visibility
Why does tooling matter in a serverless‑versus‑container debate? Because you cannot optimise what you cannot see. Binadox surfaces granular telemetry across both realms:
- Cost Explorer pinpoints sudden spikes and breaks them down by function name, memory tier or k8s namespace.
- Rightsizing advisor analyses p95 and p5 trends, suggesting new memory tiers for Lambdas or new node instance types for clusters.
- Automation Rules can automatically tag and quarantine over‑budget workloads, or send Slack alerts when GB‑seconds exceed target thresholds.
- License Manager & Renewals Calendar help finance teams map SaaS subscription renewals to the underlying cloud events they trigger, closing the loop between Cloud and SaaS governance.
Pairing those insights with periodic KPI reviews ensures that yesterday’s architecture remains tomorrow’s cost‑efficient architecture.
7. Real‑world TCO modelling
Let’s model two concrete scenarios for us‑east‑1 (pricing as of June 05, 2025):Scenario A: Low‑traffic APIScenario B: Steady micro‑service
8. Security & compliance overheads
Cost effectiveness is not purely about dollars per vCPU. A single Common Vulnerabilities and Exposures (CVE) emergency patch cycle can consume a day of engineering effort. With serverless, patching is essentially “someone else’s problem”; with containers you must redeploy images or apply in‑place fixes. However, serverless sometimes adds extra cost when you need dedicated VPC connectors, private endpoints, or SOC 2 reporting—services that clusters may already have.
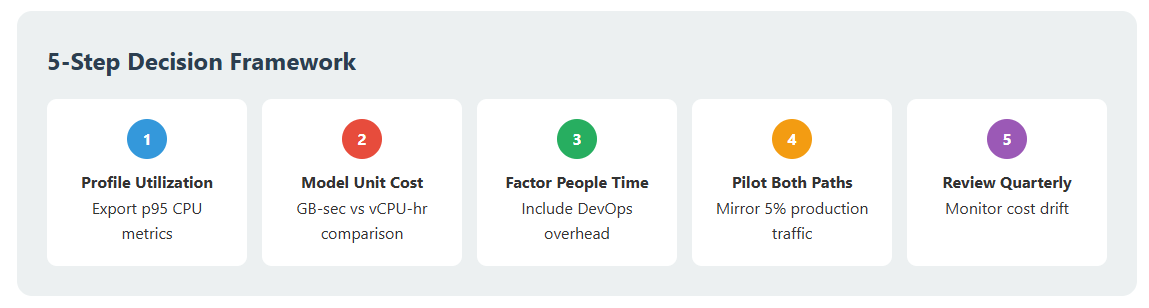
9. Five‑step decision checklist
- Profile utilisation – export p95 CPU, identify burst factor > 5.
- Model unit cost – compare GB‑sec vs vCPU‑hr under expected growth.
- Factor in people time – include DevOps headcount per architecture path.
- Pilot both paths – mirror 5 % production traffic to gather real bills.
- Review quarterly – costs drift with vendor price changes and new features.
Our cloud cost optimisation best practices template walks through that review.
10. Bottom line
Serverless shines for erratic, low‑throughput, or globally distributed workloads where you value zero‑idle billing and the ability to iterate quickly.
Containers win for high, predictable utilisation or sophisticated networking, where capacity reservations flatten the cost curve and where per‑unit pricing is dramatically lower.
Rule of thumb: under ~20 % average CPU, serverless is usually cheaper; over ~40 %, well‑tuned containers (ideally on spot or reserved instances) generally prevail.
Whichever route you choose, linking it to a cloud & SaaS management platform—complete with rightsizing insights, budget alerts, and spend dashboards—keeps your cloud and SaaS strategy healthy long‑term.