
Cloud teams crave scalable and budget-friendly compute. Pairing Terraform—the leading Infrastructure-as-Code (IaC) tool—with discounted Spot Instances from AWS, Azure or Google Cloud unlocks precisely that: automated deployment of the market’s cheapest capacity, described entirely in code. Add Binadox’s unified cloud and SaaS cost management platform on top, and the savings keep rolling in.

What Is Terraform?
Terraform is an open‑source IaC engine created by HashiCorp that turns plain‑text configuration files (written in HashiCorp Configuration Language, or HCL) into live, managed infrastructure across more than 300 providers—from AWS and Microsoft Azure to GitHub, Datadog, and even SaaS platforms. You write a desired state, run terraform plan to preview the delta, then terraform apply to let Terraform build—or change—real resources until they exactly match your blueprint.
Unlike imperative scripts, Terraform’s declarative approach means you describe what you want, not how to do it. Terraform computes the graph of dependencies, orders resource creation, handles parallelism, and stores state so future runs remain idempotent. This model offers four immediate benefits:
- Version‑controlled infrastructure: HCL files live in Git the same way your application code does, enabling pull‑request workflows, code reviews and audits.
- Reusable modules: Teams can package best practices into shareable components, reducing duplication.
- Provider‑agnostic workflows: A single CLI workflow can spin up EC2 instances, Cloudflare records and Slack channels in one run.
- Automated drift correction: When reality drifts from code—someone clicks in the cloud console—Terraform detects and can reconcile the difference.
Pro Tip:
Pair Terraform with a remote backend such as S3 + DynamoDB, Terraform Cloud or Binadox’s state‑locking integration to keep collaboration safe and conflict‑free.
Because Terraform orchestrates resources before they are created, it’s the perfect control plane for cost‑centric orchestration strategies like mixing On‑Demand and Spot capacity.
What Are Spot Instances?
Spot Instances are unused compute capacity that providers auction off—often 70‑90 % cheaper than on‑demand prices. Perfect for stateless micro‑services, CI/CD pipelines, big‑data crunching and container clusters, spots deliver enterprise‑class performance without enterprise‑class invoices. Explore the details in our AWS Spot Instances deep dive.
The trade‑off is that a provider can reclaim Spot capacity at any time. Yet with the right architecture and failover logic, interruptions become routine signals rather than emergencies.
Why Combine Terraform + Spot?
| Benefit | Description |
|---|---|
| Automated savings | Cost‑saving policies live in code; every terraform apply provisions the cheapest capacity available. |
| Governance & Audit | Version‑controlled HCL files prevent expensive surprises and pass compliance reviews. |
| Predictable scaling | Auto Scaling Groups mix on‑demand and spot capacity to guarantee baseline SLAs while harvesting discounts. |
| Rapid redeploy | If a spot VM is reclaimed, your orchestrator recreates it elsewhere in minutes. |
| Multi‑cloud optionality | Switch from AWS to Azure spot pools—or run both—without rewriting pipelines. |
Need a refresher on IaC fundamentals? Check out our primer on Infrastructure as Code.
How Spot Pricing Works
- Dynamic market prices: each instance family and Availability Zone has its own floating rate.
- Reclaim notice: AWS gives 2‑minute warnings (Azure/GCP ≈30 s) before termination.
- Billing granularity: you pay per‑second or per‑minute at the current spot rate.
- Price caps: set a max price; Terraform can fall back to on‑demand automatically.
- Historical data access: AWS publishes 3‑month spot price history, which you can query with the
aws ec2 describe-spot-price-historyAPI for predictive models.
While spot prices generally trend downward over long periods, short spikes do occur—especially around major sales events (Black Friday) or regional outages. Monitoring tools like Binadox feed this volatility into anomaly‑detection rules so teams don’t wake up to bill shocks.
Handling Interruptions the Right Way
Spot interruptions aren’t failures; they’re events you can architect around. Modern workloads—containers, serverless functions, Hadoop clusters—can absorb node churn effortlessly. Below are concrete design techniques.
- Stateless by design: offload state to managed databases (S3, RDS, BigQuery) so compute nodes become ephemeral cattle, not pets.
- Checkpoint long jobs: save ML training checkpoints every N minutes to object storage and resume on a fresh node.
- Mixed instance policies: keep e.g. 30 % on‑demand, 70 % spot for guaranteed baseline.
- Lifecycle hooks: gracefully drain K8s nodes before termination—
preStophooks, Pod Disruption Budgets and theaws-node-termination-handlerDaemonSet help here. - Capacity rebalance: enable AWS’s
capacity_rebalanceflag so the Auto Scaling Group proactively launches replacement spots before old ones terminate. - Fallback to Fargate: in extreme shortage scenarios, shift pods into serverless containers at a higher price but zero downtime.
Step-by-Step Terraform Implementation
Below is a distilled example focused on AWS, but the same patterns translate to Azure VM Scale Sets and Google Managed Instance Groups.
Define variables for flexibility
variable "spot_allocation_strategy" {
description = "How AWS chooses Spot pools"
default = "capacity-optimized"
}
variable "on_demand_base" {
default = 1 # keep 1 OD instance
}
variable "spot_percentage" {
default = 70
}Create a Launch Template
resource "aws_launch_template" "web" {
name_prefix = "web-lt-"
instance_type = "t3.large"
ami = data.aws_ami.ubuntu.id
instance_market_options {
market_type = "spot"
spot_options {
max_price = "0.05"
spot_instance_type = "one-time"
}
}
tag_specifications {
resource_type = "instance"
tags = {
Name = "web-spot"
Env = var.environment
Owner = "team-devops"
}
}
}Build an Auto Scaling Group with mixed capacity
resource "aws_autoscaling_group" "web" {
desired_capacity = 3
max_size = 6
min_size = 1
vpc_zone_identifier = data.aws_subnets.private.ids
mixed_instances_policy {
instances_distribution {
on_demand_base_capacity = var.on_demand_base
on_demand_percentage_above_base_capacity = 100 - var.spot_percentage
spot_allocation_strategy = var.spot_allocation_strategy
spot_instance_pools = 3
}
launch_template {
launch_template_specification {
launch_template_id = aws_launch_template.web.id
version = "$Latest"
}
override {
instance_type = "t3a.large"
}
override {
instance_type = "t4g.medium"
}
}
}
lifecycle {
create_before_destroy = true
}
}Add an EventBridge rule to pipe spot interruption notices into an SNS topic or Slack channel—crucial for observability.
Run terraform plan & apply—your infrastructure is now cost‑efficient and repeatable.
Best Practices & Recommended Modules
- Capacity‑Optimized strategy chooses pools with the least interruption risk.
- Favor newer instance families (
c7g,m7g)—they usually have more spare capacity and lower cost per vCPU. - Standardize tagging across stacks for cleaner cost breakdowns. Binadox aggregates these tags so finance teams can map spend to cost centers automatically.
- Integrate
infracostin pull requests to expose spend before merging; Binadox’s GitHub App posts complementary insights about SaaS license overages in the same PR. - Use Terragrunt or CloudWorkspaces to avoid code duplication when rolling identical Spot patterns across dev, staging and prod.
- Apply the 24‑hour rule: for workloads exceeding 24 h, benchmark Reserved Instances vs. Spot to ensure optimal mix.
- Enable continuous drift detection and budget alerts in Binadox’s IaC Cost Tracker, then connect Slack or Teams for real‑time notifications.
Real-World Savings Example
A fast‑growing SaaS company swapped eight on‑demand m5.large web nodes for a 70/30 spot–on‑demand mix. Engineering time invested: two Terraform pull requests plus one Binadox dashboard baseline.
| Node Type | Qty | $/hr each | Monthly (730 h) |
|---|---|---|---|
| On‑Demand | 3 | $0.096 | $210 |
| Spot | 7 | $0.028 | $143 |
| Total | $353 | ||
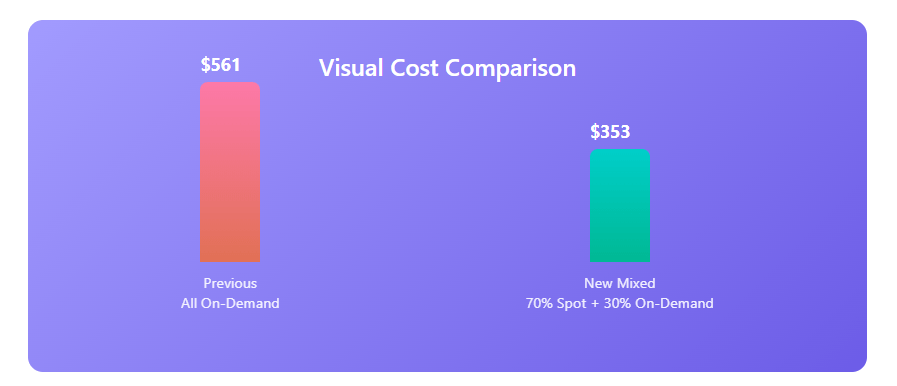
The prior all on‑demand cost was $561—37 % lower cloud bill. Equally important, Binadox detected idle development RDS instances during the same timeframe, trimming a further $90 per month and underscoring the value of holistic visibility across cloud and SaaS.
Track IaC Costs Automatically with Binadox
Managing dozens of Terraform stacks is tough. Binadox IaC Cost Tracker solves three pain points:
- Pre‑deployment estimates—see projected spend for every
terraform plan; approve or reject changes in the pull‑request conversation. - Unified cloud + SaaS dashboard shows both cloud resources and SaaS subscriptions in one place, eliminating swivel‑chair spend analysis.
- Smart recommendations—rightsizing rules, anomaly alerts and automation to keep usage in check. Binadox can trigger automatic Terraform runs or ServiceNow tickets when savings exceed a threshold you define.
Connecting Binadox takes less than 15 minutes: point the platform at your AWS Organization, Git repositories and SaaS identity provider, then let the data stream in. Within an hour you’ll see:
- Line‑item breakdowns by account, tag and service.
- Projected month‑end spend vs. budget.
- Instant alerts for rogue on‑demand instances.
- SaaS license utilization heatmaps to reclaim unused seats.
Interested in other optimization tactics? Explore our list of top cloud cost management tools and evergreen cloud cost optimisation best practices.
Conclusion
By declaring infrastructure in Terraform and letting cloud providers furnish it with Spot capacity, teams unlock cloud savings at scale. Layering Binadox on top turns ad‑hoc wins into an automated cost‑governance workflow, giving Finance and DevOps continuous visibility across cloud and SaaS landscapes.
Next step: Containerise a stateless service, convert its Auto Scaling Group to a spot mix, and watch your next invoice shrink—confident that Binadox will keep it that way. As you iterate, capture each architecture upgrade in Terraform, feed cost deltas into Binadox, and cultivate a culture where every pull request considers both reliability and dollars‑per‑hour.