
Artificial Intelligence (AI) and Machine Learning (ML) have revolutionized how businesses process data, make decisions, and deliver innovative solutions. However, the computational demands of AI workloads present unique challenges in cloud environments, requiring specialized optimization strategies that differ significantly from traditional application hosting.
The exponential growth in AI adoption has created an urgent need for organizations to master the art of managing compute-intensive workloads efficiently while controlling costs. AI applications often require substantial computational resources, specialized hardware like GPUs and TPUs, and massive storage capacities for training datasets and model artifacts.
This comprehensive guide delves into the intricacies of optimizing cloud infrastructure specifically for AI workloads. We’ll explore how to balance performance requirements with cost considerations, implement affordable cloud services that scale dynamically, and establish governance frameworks that prevent runaway spending while maintaining the computational power necessary for advanced AI operations.
By understanding the unique characteristics of AI workloads and implementing strategic optimization approaches, organizations can harness the full potential of cloud computing for artificial intelligence while maintaining financial control and operational efficiency.
What Are AI Workloads in the Cloud?
AI workloads in cloud computing refer to computational tasks and processes specifically designed to support artificial intelligence and machine learning operations. These workloads encompass a broad spectrum of activities, from data preprocessing and model training to inference and real-time prediction serving.
Unlike traditional web applications or database workloads, AI workloads are characterized by their intensive computational requirements, sporadic resource demands, and need for specialized hardware accelerators. They typically involve processing large volumes of data, performing complex mathematical operations, and requiring significant memory bandwidth.
Key Characteristics of AI Workloads
- Compute-Intensive Processing: AI workloads demand substantial computational power, often requiring parallel processing capabilities to handle complex algorithms efficiently. This includes training deep neural networks, processing natural language, computer vision tasks, and running sophisticated optimization algorithms.
- Variable Resource Requirements: Unlike steady-state applications, AI workloads exhibit highly variable resource consumption patterns. Training phases may require maximum computational resources for hours or days, while inference workloads might need burst capacity to handle real-time requests.
- Specialized Hardware Dependencies: Many AI applications benefit significantly from specialized processors such as Graphics Processing Units (GPUs), Tensor Processing Units (TPUs), or custom AI accelerators that provide optimized performance for specific mathematical operations.
- Data-Intensive Operations: AI workloads typically process massive datasets, requiring high-performance storage systems and efficient data pipeline architectures to minimize bottlenecks during training and inference phases.
Understanding AI Compute Requirements
Managing compute resources for AI workloads requires a deep understanding of different processing patterns and their corresponding infrastructure needs. The key to successful cloud cost optimization lies in matching workload characteristics with appropriate compute configurations.
Training vs. Inference Workloads
Training Workloads represent the most resource-intensive phase of AI development. During model training, systems process entire datasets multiple times, adjusting model parameters through iterative optimization processes. These workloads typically require:
- High-memory instances with substantial RAM capacity for loading large datasets
- Multiple GPU or TPU instances for parallel processing
- High-bandwidth network connectivity for distributed training scenarios
- Persistent storage systems for checkpoint saving and model versioning
Inference Workloads focus on serving trained models to make predictions on new data. These workloads prioritize low latency and high throughput rather than raw computational power. Inference requirements include:
- Optimized instance types with balanced CPU-to-memory ratios
- Specialized inference accelerators for cost-effective prediction serving
- Auto-scaling capabilities to handle variable request volumes
- Edge computing integration for reduced latency applications
Batch vs. Real-Time Processing
Batch Processing handles large volumes of data in scheduled intervals, making it ideal for training jobs, data preprocessing, and offline analytics. Batch workloads benefit from:
- Spot instances and preemptible resources for cost reduction
- Flexible scheduling to take advantage of lower pricing periods
- High-capacity storage systems for processing large datasets
- Automated resource provisioning and deprovisioning
Real-Time Processing requires immediate response to incoming data streams, supporting applications like fraud detection, recommendation engines, and autonomous systems. Real-time workloads need:
- Always-on instances with guaranteed availability
- Low-latency networking and storage configurations
- Redundant deployments for high availability
- Sophisticated monitoring and alerting systems
Storage Optimization for AI Applications
Storage represents a critical component of AI infrastructure, often accounting for a significant portion of overall cloud costs. Affordable cloud infrastructure strategies must address both performance and cost considerations for different types of data used in AI workloads.
Data Lifecycle Management
Implementing effective data lifecycle management strategies helps organizations optimize storage costs while maintaining accessibility for active AI workloads. This involves categorizing data based on access patterns and business value:
Hot Data includes actively used datasets, model artifacts, and real-time inference data that require high-performance storage with immediate accessibility. This data typically resides on premium storage tiers with SSD-based systems.
Warm Data encompasses less frequently accessed datasets, historical training data, and archived model versions that may be needed for retraining or compliance purposes. This data can be stored on standard storage tiers with moderate performance characteristics.
Cold Data consists of long-term archives, compliance datasets, and historical data that’s rarely accessed but must be retained for regulatory or business continuity reasons. Cold data storage utilizes the most cost-effective storage classes with higher retrieval latencies.
Storage Architecture Patterns
- Data Lakes provide centralized repositories for storing vast amounts of structured and unstructured data in their native formats. Data lakes offer cost-effective storage for AI workloads by eliminating the need for extensive data transformation before storage.
- Feature Stores serve as centralized repositories for engineered features used across multiple AI models and applications. Feature stores reduce redundant data processing and ensure consistency across different AI workloads.
- Distributed File Systems enable high-performance access to large datasets across multiple compute instances, supporting parallel processing requirements common in AI training workloads.
Cloud Infrastructure Models for AI
Different cloud infrastructure models offer varying levels of control, flexibility, and cost optimization opportunities for AI workloads. Understanding these models helps organizations choose the most appropriate approach for their specific requirements.
Infrastructure as a Service (IaaS)
IaaS provides maximum control over the computing environment, allowing organizations to customize AI infrastructure according to specific performance and security requirements. This model offers:
- Complete control over instance configurations and software stacks
- Flexibility to install specialized AI frameworks and libraries
- Ability to optimize networking and storage configurations
- Responsibility for managing operating systems and runtime environments
Platform as a Service (PaaS)
PaaS solutions abstract infrastructure management complexities while providing AI-optimized environments. Benefits include:
- Pre-configured AI/ML runtime environments and frameworks
- Managed scaling and resource allocation
- Integrated development and deployment toolchains
- Reduced operational overhead for infrastructure management
AI-Specialized Services
Cloud providers offer specialized AI services that eliminate infrastructure management entirely:
- Managed machine learning platforms for end-to-end AI workflows
- Pre-trained models and APIs for common AI tasks
- AutoML services that automate model development processes
- Serverless inference platforms for cost-effective model serving
For organizations seeking deeper insights into cloud infrastructure decisions, our comprehensive guide on cloud management strategy provides valuable frameworks for evaluation and selection.
Benefits of Cloud-Optimized AI Infrastructure
Implementing properly optimized cloud infrastructure for AI workloads delivers significant advantages across multiple dimensions of business operations and technical performance.
Cost Efficiency and Financial Predictability
Cloud optimization for AI workloads transforms unpredictable infrastructure expenses into manageable, scalable costs. Organizations benefit from:
Dynamic Resource Allocation enables paying only for computational resources during active use, eliminating the need for maintaining expensive on-premises hardware that sits idle between training cycles.
Automated Cost Controls through automated cloud expense tracking help prevent budget overruns by monitoring resource utilization and implementing automatic scaling policies that align with business requirements.
Flexible Pricing Models including spot instances, reserved capacity, and preemptible resources provide opportunities to reduce compute costs significantly for batch processing and training workloads that can tolerate interruptions.
Performance and Scalability Advantages
Elastic Scaling capabilities allow AI infrastructure to automatically adjust resource allocation based on workload demands, ensuring optimal performance during peak processing periods while minimizing costs during low-activity phases.
Access to Cutting-Edge Hardware through cloud providers enables organizations to leverage the latest GPU architectures, specialized AI accelerators, and high-performance computing resources without large capital investments.
Global Distribution capabilities support deploying AI models closer to end-users, reducing latency for real-time applications and improving overall user experience.
Operational Efficiency Improvements
Managed Services Integration reduces operational overhead by leveraging cloud-native AI services for common tasks like data preprocessing, model training, and inference serving.
Automated Backup and Recovery ensures critical AI assets including trained models, datasets, and configuration files are protected against data loss and can be quickly restored when needed.
Enhanced Collaboration through cloud-based AI platforms enables distributed teams to work together on AI projects, sharing resources, datasets, and model artifacts seamlessly.
Current State of the AI Cloud Market
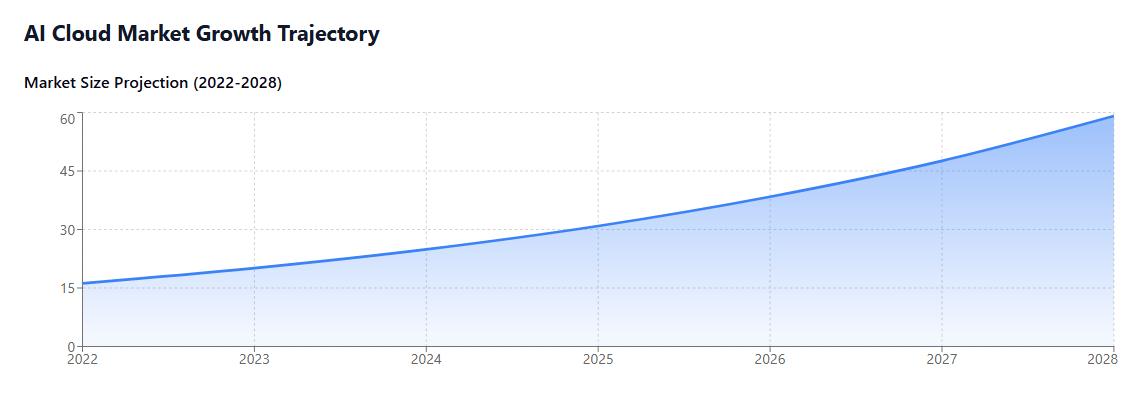
The AI cloud computing market has experienced unprecedented growth as organizations across industries embrace artificial intelligence technologies. According to recent market research, the global AI cloud services market reached $16.2 billion in 2022 and is projected to grow at a compound annual growth rate (CAGR) of 24.1% through 2028.
This explosive growth is driven by several key factors that make affordable cloud services increasingly attractive for AI workloads. Organizations are recognizing the cost advantages of cloud-based AI infrastructure compared to building and maintaining dedicated on-premises hardware.
Market Adoption Patterns
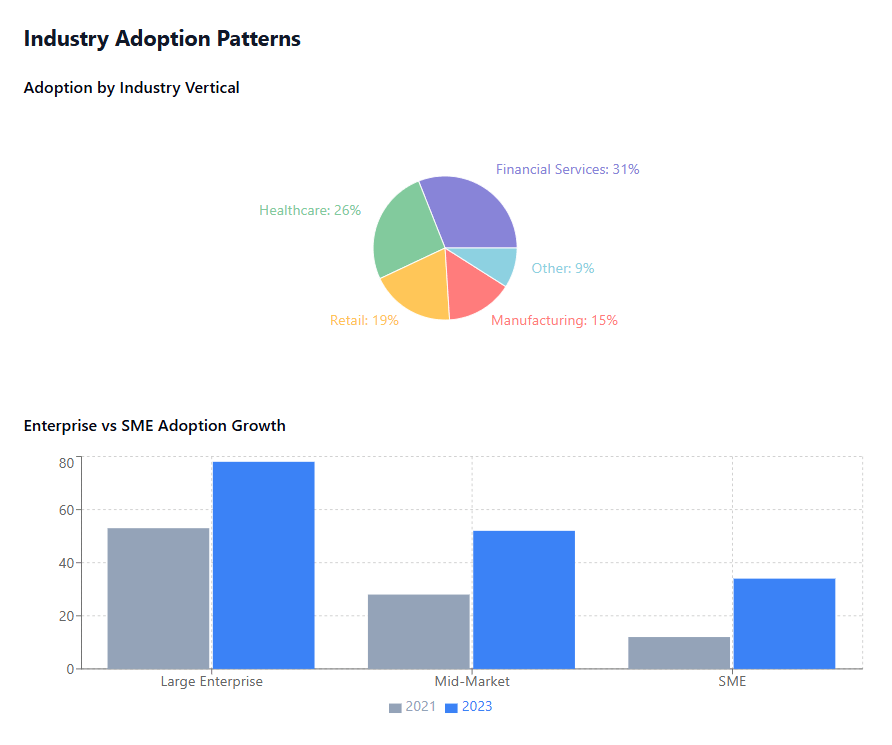
Enterprise Adoption has accelerated significantly, with 78% of large enterprises now using cloud-based AI services for at least some of their machine learning workloads. This represents a 45% increase from 2021, indicating rapid mainstream adoption.
Industry Vertical Growth shows particularly strong adoption in financial services (31%), healthcare (26%), and retail (19%) sectors, where AI applications deliver immediate business value through improved decision-making and customer experiences.
Small and Medium Business Penetration has increased dramatically as cloud providers offer more accessible AI services and affordable scaling solutions that don’t require substantial upfront investments.
Geographic Distribution
The adoption of cloud-based AI infrastructure varies significantly across regions, with North America leading at 42% of global usage, followed by Asia-Pacific at 31% and Europe at 21%. This distribution reflects both technological infrastructure maturity and regulatory environments that influence cloud adoption decisions.
Cost Optimization Trends
Organizations are increasingly focusing on cloud cost optimization strategies specifically designed for AI workloads. Recent surveys indicate that 67% of companies using cloud-based AI report achieving cost savings of 30-50% compared to on-premises alternatives through effective resource management and optimization practices.
The growing emphasis on FinOps practices for AI workloads reflects the need for better financial governance as AI projects scale from experimental phases to production deployments with significant resource requirements.
Emerging Trends in AI Cloud Computing
The landscape of AI cloud computing continues to evolve rapidly, with several emerging trends reshaping how organizations approach infrastructure optimization and resource management for artificial intelligence workloads.
Rise of Edge AI and Hybrid Deployments
Edge AI represents a fundamental shift toward distributed AI processing, bringing computation closer to data sources and end-users. This trend is driven by requirements for reduced latency, improved privacy, and bandwidth optimization.
Edge-Cloud Hybrid Models are emerging as organizations seek to balance the benefits of centralized cloud processing with the advantages of edge deployment. These architectures enable real-time inference at the edge while maintaining centralized training and model management in cloud environments.
5G Integration is accelerating edge AI adoption by providing the high-bandwidth, low-latency connectivity necessary for sophisticated AI applications at network edges. This integration enables new use cases in autonomous vehicles, industrial automation, and augmented reality applications.
Privacy-Preserving AI techniques like federated learning are gaining traction, allowing organizations to train AI models across distributed datasets without centralizing sensitive information in cloud environments.
Integration of Specialized AI Hardware
Cloud providers are rapidly expanding their offerings of specialized AI accelerators beyond traditional GPUs, introducing purpose-built processors optimized for specific AI workload patterns.
Tensor Processing Units (TPUs) and similar AI-specific processors provide significant performance and cost advantages for certain types of machine learning workloads, particularly those involving large-scale matrix operations common in deep learning.
Field-Programmable Gate Arrays (FPGAs) offer flexible acceleration capabilities that can be customized for specific AI algorithms, providing optimal performance for specialized applications while maintaining cost efficiency.
Quantum Computing Integration is beginning to emerge in cloud environments, offering potential breakthrough capabilities for certain classes of AI problems, particularly optimization and simulation tasks.
Sustainable AI Computing Initiatives
Environmental sustainability is becoming a critical consideration in AI cloud infrastructure design, driven by the significant energy consumption associated with large-scale AI training and inference workloads.
Carbon-Aware Computing involves optimizing AI workload scheduling to utilize renewable energy sources and minimize carbon footprint while maintaining performance requirements.
Efficient Model Architectures and techniques like model compression, quantization, and pruning are being integrated into cloud AI platforms to reduce computational requirements without sacrificing accuracy.
Green Cloud Regions optimized for renewable energy usage are becoming important factors in cloud resource allocation decisions for environmentally conscious organizations.
Examples of Good and Poor AI Cloud Spending Practices
Understanding the difference between effective and ineffective spending patterns helps organizations avoid common pitfalls while maximizing the value derived from AI cloud investments.
Good AI Cloud Spending Practices
- Workload-Specific Resource Optimization: Successful organizations carefully match compute resources to specific AI workload requirements. For example, using high-memory instances for data preprocessing tasks, GPU-optimized instances for model training, and CPU-optimized instances for lightweight inference workloads.
- Automated Resource Lifecycle Management: Implementing automated policies that provision resources when needed and deallocate them when idle prevents unnecessary costs from accumulating. This includes automatically stopping training jobs that have completed and scaling down inference endpoints during low-traffic periods.
- Strategic Use of Spot Instances: Leveraging spot instances for fault-tolerant training workloads can reduce compute costs by 70-90% compared to on-demand pricing. Organizations achieve significant savings by designing training pipelines that can handle interruptions gracefully through checkpointing and automatic restart mechanisms.
- Data Storage Optimization: Implementing intelligent data tiering strategies that automatically move older datasets to lower-cost storage classes while maintaining accessibility for active AI workloads. This includes using lifecycle policies to transition training data through hot, warm, and cold storage tiers based on access patterns.
- Cross-Project Resource Sharing: Establishing shared resource pools for development and experimentation environments allows multiple AI teams to utilize the same infrastructure efficiently, reducing overall costs while maintaining productivity.
Poor AI Cloud Spending Practices
- Always-On Resource Provisioning: Many organizations fail to implement proper resource management, leaving expensive GPU instances running continuously even when not actively training models or serving predictions. This practice can result in monthly costs that are 5-10 times higher than necessary.
- Oversized Instance Selection: Choosing instance types with excessive computational capacity for the actual workload requirements leads to significant waste. This often occurs when teams select the largest available instances without analyzing their specific performance needs.
- Lack of Cost Monitoring and Alerting: Organizations that don’t implement proper cloud cost anomaly detection often discover budget overruns only after receiving monthly bills, missing opportunities for timely intervention and cost control.
- Redundant Data Storage: Maintaining multiple copies of the same datasets across different projects and environments without implementing proper data management strategies leads to unnecessary storage costs that can accumulate rapidly with large AI datasets.
- Inadequate Resource Governance: Allowing individual developers or teams to provision resources without approval processes or spending limits often results in uncontrolled cost growth and resource sprawl across cloud environments.
How to Optimize AI Cloud Costs and Manage Resources
Effective cost optimization for AI workloads requires a comprehensive approach that addresses resource management, workload scheduling, and financial governance across the entire AI development lifecycle.
AI-Specific Cost Management Tools
Implementing specialized cost management tools designed for AI workloads provides essential visibility and control capabilities that generic cloud cost management solutions often lack.
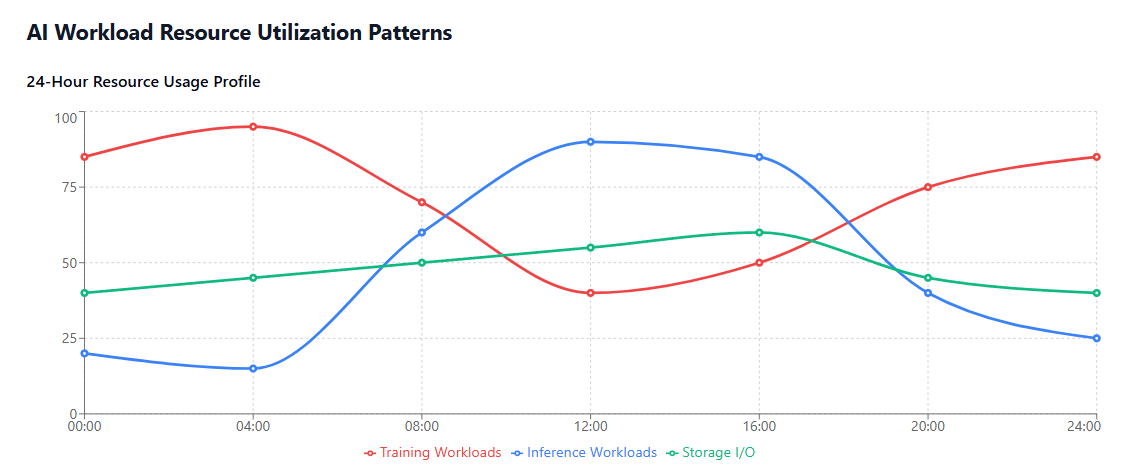
ML-Aware Resource Monitoring tools track resource utilization patterns specific to machine learning workloads, including GPU utilization rates, memory bandwidth usage, and storage I/O patterns. These tools provide insights that enable more precise resource rightsizing and scheduling optimization.
Model Performance vs. Cost Analytics platforms help organizations understand the relationship between infrastructure investment and model performance, enabling data-driven decisions about resource allocation and architecture choices.
Automated Workload Scheduling systems optimize resource utilization by automatically scheduling training jobs during periods of lower demand or when spot instance pricing is most favorable, while ensuring critical inference workloads maintain required performance levels.

Centralized AI Resource Governance
Establishing centralized governance frameworks for AI resources prevents uncontrolled spending while enabling innovation and experimentation across AI teams.
Resource Request and Approval Workflows ensure that significant resource allocations undergo appropriate review and alignment with business objectives and budget constraints. This includes establishing different approval thresholds for development, staging, and production environments.
Shared Resource Pools for common AI infrastructure components like data preprocessing environments, model registry systems, and development platforms reduce overall costs through economies of scale while maintaining team productivity.
Budget Allocation and Tracking by project, team, or business unit provides clear accountability and enables better financial planning for AI initiatives. This includes implementing automated alerts when spending approaches predefined thresholds.
Dynamic Resource Rightsizing for AI Workloads
AI workloads exhibit unique resource utilization patterns that require specialized rightsizing approaches different from traditional application workloads.
Training Job Optimization involves analyzing historical performance data to determine optimal instance configurations for different types of model training tasks. This includes selecting appropriate GPU types, memory configurations, and networking requirements based on model architecture and dataset characteristics.
Inference Endpoint Scaling requires balancing cost efficiency with performance requirements, including implementing auto-scaling policies that can handle variable prediction request volumes while minimizing infrastructure costs during low-traffic periods.
Development Environment Management includes providing cost-effective development environments that can be quickly provisioned and deprovisioned as needed, while ensuring developers have access to representative datasets and computational resources for effective experimentation.
Evaluating AI Cloud Service Alternatives
Regular evaluation of AI cloud service options helps organizations optimize costs while staying current with rapidly evolving service offerings and pricing models.
Multi-Cloud Cost Comparison involves analyzing pricing, performance, and feature differences across cloud providers for specific AI workload types. This includes considering factors like data transfer costs, storage pricing, and specialized AI service availability.
Service Migration Planning for optimizing existing AI workloads through service upgrades, provider changes, or architectural modifications that can deliver better cost-performance ratios.
Vendor Negotiation Strategies for organizations with significant AI cloud spending, including volume discounts, committed use discounts, and custom pricing arrangements based on long-term usage commitments.
Implementing AI Governance Policies
Comprehensive governance policies ensure that AI cloud resources are used efficiently and in alignment with organizational objectives and constraints.
Resource Usage Policies establish guidelines for appropriate use of different instance types, storage classes, and AI services based on workload characteristics and business requirements.
Cost Accountability Frameworks assign clear ownership and responsibility for AI cloud spending decisions, including regular review processes and performance metrics that align technical decisions with business outcomes.
Security and Compliance Integration ensures that cost optimization efforts don’t compromise security requirements or regulatory compliance obligations, particularly important for AI workloads processing sensitive data.
Improve AI Cloud Management with Binadox
Managing AI workloads in cloud environments presents unique challenges that require specialized tools and approaches beyond traditional cloud management platforms. Binadox addresses these challenges by providing comprehensive visibility, optimization, and governance capabilities specifically designed for complex, resource-intensive AI workloads.
AI Workload Visibility and Analytics
Binadox provides deep insights into AI workload patterns and resource utilization that enable more informed optimization decisions. The platform automatically discovers and catalogs AI resources across multiple cloud providers, providing a unified view of distributed AI infrastructure.
ML-Specific Resource Tracking monitors specialized AI resources including GPU instances, TPU allocations, and AI-optimized storage systems, providing detailed utilization metrics and cost attribution that generic cloud monitoring tools often miss.
Workload Pattern Analysis identifies usage patterns specific to AI workloads, including training vs. inference resource consumption, batch processing schedules, and seasonal demand variations that impact resource planning and cost optimization strategies.
Performance-Cost Correlation analytics help organizations understand the relationship between infrastructure spending and AI model performance, enabling data-driven decisions about resource allocation and architectural choices.
Automated Cost Optimization for AI
The platform implements automated optimization strategies specifically designed for the unique characteristics of AI workloads, including variable resource demands and specialized hardware requirements.
Intelligent Resource Scheduling automatically schedules training jobs and other batch AI workloads to take advantage of optimal pricing windows, including spot instance availability and off-peak demand periods.
Dynamic Scaling for Inference implements sophisticated auto-scaling policies for AI inference endpoints that balance cost efficiency with performance requirements, including predictive scaling based on historical demand patterns.
Storage Lifecycle Management for AI datasets and model artifacts automatically transitions data through appropriate storage tiers based on access patterns and retention requirements, significantly reducing storage costs for large AI datasets.
AI-Focused Financial Governance
Binadox provides financial governance capabilities tailored to the unique spending patterns and approval workflows common in AI development organizations.
Project-Based Cost Attribution enables accurate cost allocation for AI projects that may utilize shared resources across multiple teams, departments, or business units, providing clear accountability for AI infrastructure spending.
Budget Controls and Alerting implement sophisticated budget management features that account for the variable nature of AI workload spending, including predictive alerting based on historical usage patterns and planned training schedules.
ROI Analysis for AI Investments provides frameworks for measuring and reporting on the business value generated by AI infrastructure investments, helping organizations justify continued investment and optimize resource allocation decisions.
Multi-Cloud AI Resource Management
For organizations utilizing multiple cloud providers for AI workloads, Binadox provides unified management capabilities that simplify complex multi-cloud AI architectures.
Cross-Cloud Resource Discovery automatically identifies and catalogs AI resources across AWS, Azure, Google Cloud, and other cloud providers, providing a single pane of glass view of distributed AI infrastructure.
Unified Cost Reporting aggregates costs across multiple cloud providers and currencies, providing accurate total cost of ownership calculations for AI initiatives that span multiple cloud environments.
Optimization Recommendations consider cross-cloud resource options and pricing differences, helping organizations make informed decisions about workload placement and resource allocation across multiple cloud providers.
By leveraging Binadox’s specialized AI cloud management capabilities, organizations can achieve significant cost reductions while maintaining or improving AI workload performance, enabling more ambitious AI initiatives within controlled budget parameters.
Conclusion
The optimization of cloud infrastructure for AI workloads represents a critical capability for organizations seeking to leverage artificial intelligence technologies effectively while maintaining financial discipline. As AI applications become increasingly central to business operations across industries, the ability to manage compute and storage resources efficiently at scale becomes a competitive differentiator.
Successful AI cloud optimization requires understanding the unique characteristics of AI workloads, including their variable resource demands, specialized hardware requirements, and data-intensive processing patterns. Organizations that implement comprehensive optimization strategies encompassing automated cloud expense tracking, intelligent resource scheduling, and sophisticated cost governance frameworks achieve significant cost reductions while enabling more ambitious AI initiatives.
The evolving landscape of AI cloud computing, including the emergence of edge AI deployments, specialized hardware accelerators, and sustainable computing practices, continues to create new opportunities for optimization and cost reduction. Organizations that stay current with these trends and continuously refine their optimization approaches will be best positioned to maximize the business value of their AI investments.
Through implementing best practices for AI workload management, leveraging specialized cost optimization tools, and establishing robust governance frameworks, businesses can harness the transformative power of artificial intelligence while maintaining operational efficiency and financial control. The key to success lies in treating AI cloud optimization as an ongoing strategic capability rather than a one-time implementation, continuously adapting approaches as workloads evolve and new technologies emerge.
As the AI cloud computing market continues its rapid expansion, organizations that master the art of efficient resource management will be able to pursue more innovative and impactful AI applications, ultimately driving greater business value from their artificial intelligence initiatives while maintaining sustainable cost structures in the dynamic world of cloud computing.