Introduction
Artificial Intelligence (AI) and Machine Learning (ML) have become essential drivers of digital transformation, powering everything from personalized recommendations to advanced medical diagnostics. Yet, behind these innovations lies a growing challenge: the high cost of GPU workloads in cloud environments.
While cloud computing has made large-scale ML training more accessible, GPU instances—necessary for deep learning, neural networks, and generative AI—remain one of the most expensive cloud resources. Businesses that fail to manage these costs risk overspending, underutilization, and reduced ROI on their ML initiatives.
The COVID-19 pandemic further accelerated AI adoption, as organizations rapidly shifted to digital-first strategies and cloud-driven innovation (Binadox research). This new reality makes cost optimization not just a financial necessity but a competitive advantage.
Why GPU Costs Matter in AI/ML Workloads
GPU (Graphics Processing Unit) instances are the backbone of modern ML. Unlike CPUs, GPUs handle large-scale parallel computations—essential for training massive datasets and running complex models. However, the same features that make GPUs powerful also make them costly.
- High hourly pricing: On-demand GPU instances on AWS, Microsoft Azure, or Google Cloud can be 10–20x more expensive than CPU instances.
- Idle time wastage: Many ML workflows involve preprocessing, validation, or downtime, leaving GPUs underutilized.
- Scaling complexity: As teams scale AI projects, the lack of cost governance can lead to spiraling expenses.
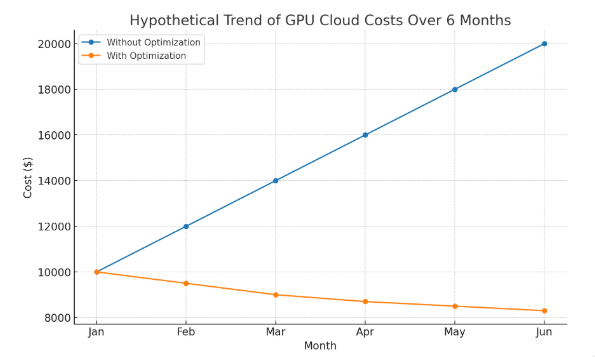
Without strategic management, organizations often pay for GPU capacity that doesn’t directly translate into business value.
Challenges of GPU Instance Management
- Unpredictable workloads – Training jobs often vary in duration and intensity, making cost forecasting difficult.
- Experimentation overhead – Data scientists frequently run multiple experiments, many of which fail or produce minimal results.
- Lack of visibility – Without centralized dashboards, teams struggle to track GPU usage across regions, projects, and clouds.
- Inefficient scaling – Using static GPU provisioning instead of elastic scaling leads to overpayment.
Cost Optimization Strategies for AI/ML GPU Workloads
Rightsizing GPU Instances
Not every ML model requires the most powerful GPU. A common mistake is overprovisioning—using NVIDIA A100s or V100s for workloads that could run on smaller T4 or P4 instances. Rightsizing ensures resources align with actual workload demands.
Platforms like Binadox offer rightsizing recommendations by analyzing historical usage patterns and suggesting cheaper instance alternatives.
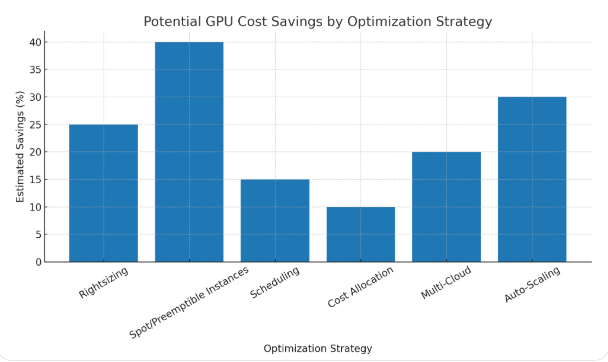
Spot and Preemptible Instances
Cloud providers offer spot instances (AWS) and preemptible VMs (GCP) at discounts of up to 90%. These are ideal for non-critical ML experiments or distributed training jobs tolerant of interruptions.
Automation rules can reassign workloads when spot instances are reclaimed, reducing risk of job failure.
Scheduling GPU Usage
Idle GPU time often accounts for hidden waste. By scheduling workloads to run only during active hours, teams can avoid paying for unused capacity.
For example:
- Training jobs can be run overnight.
- Development environments can automatically shut down after business hours.
Binadox automation allows policies such as “stop GPU instances if idle for 30 minutes,” ensuring costs remain under control.
Cost Allocation and Tagging
AI/ML projects often span multiple departments. Without clear tagging, it’s difficult to know which teams are responsible for GPU expenses.
Using cost allocation tags (e.g., “Project: NLP Research,” “Team: Data Science”), organizations gain granular visibility. Binadox enables spend segmentation by team, country, or project, simplifying chargebacks and accountability.
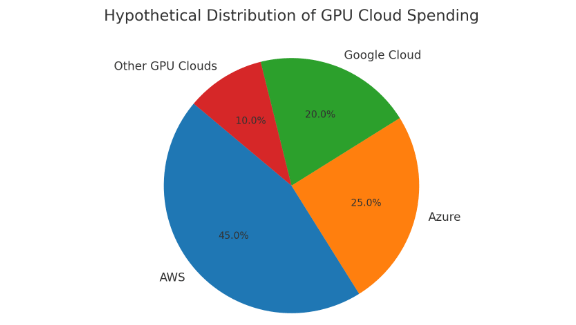
Hybrid Cloud and Multi-Cloud Approaches
Sometimes, the best GPU pricing is not in the primary cloud provider. By leveraging multi-cloud strategies, businesses can choose the most cost-effective GPU offering across AWS, Azure, GCP, or niche GPU cloud vendors.
Binadox dashboards consolidate all multi-cloud spending into a single view, helping organizations compare and optimize costs.
Auto-Scaling for Training Jobs
Instead of allocating fixed GPU clusters, auto-scaling provisions instances dynamically based on workload demand. Kubernetes (with GPU-aware scheduling) is widely used for elastic scaling, but it requires proper monitoring.
Rightsizing combined with auto-scaling, plus real-time monitoring, prevents resource hoarding and aligns GPU usage with workload demand.
Leveraging AI in Cost Optimization
Interestingly, AI can optimize AI. ML algorithms can predict workload spikes, recommend better scheduling, or automatically reassign resources.
This creates a feedback loop where AI enhances cost management of AI workloads.
The Role of SaaS Platforms in GPU Cost Management
GPU workload optimization is not just about infrastructure—it’s also about SaaS-style management platforms. These provide centralized control, automation, and analytics across multiple clouds.
Binadox is a strong example, offering:
- Cloud and SaaS cost visibility in one dashboard
- Rightsizing and anomaly detection for GPU workloads
- Renewals calendar and license manager for SaaS and cloud contracts
- Automation rules to shut down idle GPUs or optimize instance allocation
- IaC Cost Tracker for teams adopting Terraform-based infrastructure
By combining cloud workload optimization with SaaS spend management, businesses gain full-spectrum visibility of IT costs.
Best Practices for AI/ML Cost Governance
- Set budgets and alerts – Define daily or weekly spend limits with anomaly detection.
- Conduct regular audits – Identify unused GPU clusters and cancel wasteful subscriptions.
- Centralize procurement – Prevent teams from independently spinning up GPU instances without governance.
- Encourage FinOps culture – Align developers, data scientists, and finance teams around shared cost goals.
- Trial and benchmark instances – Continuously test performance/cost trade-offs before scaling workloads.
Future Trends in AI/ML GPU Cost Optimization
- AI-native cost optimization – Predictive ML models will automate most workload placement decisions.
- Specialized cloud providers – Startups offering GPU cloud at lower rates will disrupt AWS/Azure/GCP.
- Edge GPU processing – Edge computing will handle real-time ML inference, reducing cloud dependency.
- Vertical-specific AI SaaS – Similar to SaaS verticalization, GPU services will tailor pricing and scaling to industries like healthcare or autonomous vehicles. Marketplaces such as Salesforce AppExchange and Google Workspace Marketplace will expand distribution of AI/ML SaaS tools.
Conclusion
AI/ML workloads depend heavily on GPU power—but without careful management, GPU costs can consume entire IT budgets. The solution lies in strategic cloud optimization, including rightsizing, automation, multi-cloud flexibility, and predictive governance.
Platforms like Binadox provide the visibility, automation, and insights needed to ensure GPU instances are cost-effective and aligned with business outcomes.
By adopting these practices, organizations can accelerate AI innovation while keeping costs under control—turning GPU expenses into investments that truly drive competitive advantage.