
The landscape of artificial intelligence development has undergone a revolutionary transformation in 2025, with local Large Language Models (LLMs) emerging as a cornerstone for cost-effective and privacy-conscious AI development. As businesses increasingly seek affordable cloud services and budget management for startups, the adoption of local LLMs has become a strategic imperative for organizations looking to optimize their AI development costs while maintaining complete control over their data and infrastructure.
This comprehensive guide explores the best local llm options available in 2025, providing developers and businesses with the insights needed to make informed decisions about their AI development stack. Whether you’re comparing lm studio vs jan ai or evaluating ollama vs jan ai, this article will equip you with the knowledge to choose the right tools for your specific needs.
The shift toward local LLM deployment represents more than just a cost optimization strategy—it’s a fundamental change in how organizations approach AI development, offering unprecedented control over model performance, data privacy, and operational costs. As we delve into the best local llms and best local llm models, you’ll discover how these solutions can transform your AI development workflow while significantly reducing your dependency on expensive cloud API services.
What Are Local LLMs?
Local Large Language Models represent a paradigm shift in AI development, allowing developers to run sophisticated language models directly on their own hardware infrastructure rather than relying on cloud-based API services. Unlike traditional cloud-based AI services that require constant internet connectivity and per-token billing, local LLMs operate entirely within your computing environment, providing complete control over the model’s behavior, data processing, and operational costs.
The concept of local LLMs has gained tremendous traction as organizations recognize the limitations and costs associated with cloud-based AI services. When you deploy a best local llm, you’re essentially bringing the entire AI processing capability in-house, eliminating the need for external API calls and the associated latency, cost, and privacy concerns.
Local LLMs encompass a wide range of open-source models that have been optimized for local deployment. These models range from lightweight options suitable for modest hardware configurations to powerful alternatives that can compete with the most advanced cloud-based solutions. The key advantage lies in their ability to provide consistent, predictable costs while maintaining high performance and ensuring complete data privacy.
Why Choose Local LLMs Over Cloud APIs?
The decision to adopt local LLMs over cloud APIs stems from several compelling advantages that align with modern business requirements for cost-effective cloud solutions and operational independence.
Cost Predictability and Control
One of the most significant advantages of local LLMs is their predictable cost structure. Unlike cloud APIs that charge per token or request, local LLMs require only the initial hardware investment and ongoing electricity costs. This model provides businesses with complete cost transparency and eliminates the risk of unexpected bills from high usage periods.
For organizations processing large volumes of text or requiring frequent model interactions, the cost savings can be substantial. A typical cloud API might charge $0.002 per 1K tokens, which can quickly accumulate to thousands of dollars monthly for high-volume applications. In contrast, local LLMs provide unlimited usage once deployed, making them particularly attractive for affordable software management strategies.
Data Privacy and Security
Local LLMs ensure complete data privacy by processing all information within your controlled environment. This is particularly crucial for organizations handling sensitive data, proprietary information, or operating in regulated industries. Unlike cloud-based solutions where your data travels across networks and is processed on external servers, local LLMs keep everything within your infrastructure.
Performance and Latency
Local deployment eliminates network latency associated with API calls, resulting in faster response times and improved user experience. This is especially important for real-time applications, interactive chatbots, or development workflows where speed is critical.
Customization and Fine-tuning
Local LLMs offer unprecedented customization capabilities, allowing developers to fine-tune models for specific use cases, domains, or organizational requirements. This level of customization is often limited or expensive with cloud-based services.
Top Local LLM Models for 2025
The landscape of best local llm models in 2025 is rich with options, each offering unique advantages for different use cases and hardware configurations. Here’s a comprehensive overview of the leading models:
Llama 2 and Llama 3 Series
Meta’s Llama series remains among the most popular choices for local deployment, offering excellent performance across various model sizes. The Llama 3 models, released in 2024, provide significant improvements in reasoning capabilities and coding proficiency.
Specifications:
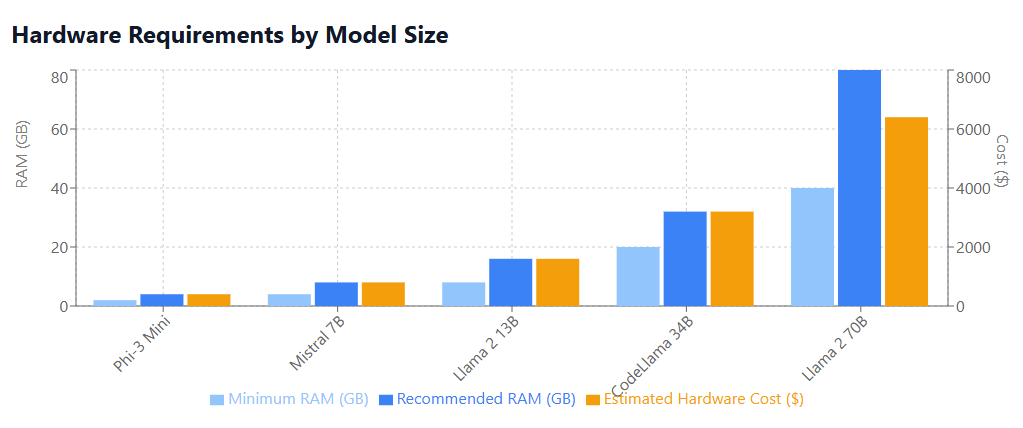
- Model sizes: 7B, 13B, 70B parameters
- Memory requirements: 4GB to 40GB+ depending on quantization
- Strengths: General-purpose tasks, coding, reasoning
- Optimal hardware: RTX 4090, RTX 4080, or equivalent
Mistral 7B and Mixtral 8x7B
Mistral AI’s models have gained significant traction for their exceptional performance-to-size ratio. The Mistral 7B model delivers remarkable results while requiring modest hardware resources, making it ideal for budget-friendly SaaS solutions.
Specifications:
- Mistral 7B: 7 billion parameters, 4GB RAM minimum
- Mixtral 8x7B: Mixture of experts architecture, 8GB+ RAM recommended
- Strengths: Multilingual capabilities, instruction following, code generation
- Optimal hardware: RTX 4060 Ti or higher
CodeLlama Series
Specifically optimized for programming tasks, CodeLlama models excel in code generation, completion, and debugging across multiple programming languages.
Specifications:
- Model sizes: 7B, 13B, 34B parameters
- Specialized versions: Code, Instruct, Python
- Memory requirements: 4GB to 20GB+
- Strengths: Code generation, debugging, explanation
Phi-3 Models
Microsoft’s Phi-3 series offers exceptional efficiency, delivering strong performance with significantly reduced computational requirements compared to larger models.
Specifications:
- Model sizes: Mini (3.8B), Small (7B), Medium (14B)
- Memory requirements: 2GB to 8GB
- Strengths: Efficiency, mobile deployment, reasoning tasks
- Optimal hardware: Compatible with most modern hardware
Gemma Series
Google’s Gemma models provide excellent performance for various tasks while being optimized for responsible AI deployment.
Specifications:
- Model sizes: 2B, 7B parameters
- Memory requirements: 2GB to 8GB
- Strengths: Safety, instruction following, multilingual support
- Optimal hardware: RTX 3060 or equivalent
Hardware Requirements and Cost Analysis
Understanding the hardware requirements for deploying best local llms is crucial for making informed decisions about your AI development infrastructure. The hardware landscape for local LLM deployment has evolved significantly, with options ranging from consumer-grade GPUs to enterprise-level configurations.
GPU Requirements by Model Size
Small Models (2B-7B parameters):
- Minimum: RTX 3060 (12GB), RTX 4060 Ti (16GB)
- Recommended: RTX 4070 (12GB), RTX 4080 (16GB)
- Memory usage: 4-8GB VRAM
- Performance: Suitable for most development tasks, prototyping
Medium Models (13B-20B parameters):
- Minimum: RTX 4080 (16GB), RTX 4090 (24GB)
- Recommended: RTX 4090 (24GB), A6000 (48GB)
- Memory usage: 8-16GB VRAM
- Performance: Production-ready for most applications
Large Models (34B-70B parameters):
- Minimum: RTX 4090 (24GB) with CPU offloading
- Recommended: A100 (40GB/80GB), H100 (80GB)
- Memory usage: 20GB+ VRAM
- Performance: Enterprise-level capabilities
Cost Analysis Framework
When evaluating the cost-effectiveness of local LLM deployment, consider these factors:
Initial Hardware Investment:
- Consumer GPU (RTX 4090): $1,600-$2,000
- Professional GPU (A6000): $4,000-$5,000
- Enterprise GPU (H100): $25,000-$40,000
Operational Costs:
- Electricity: $50-$200/month (depending on usage and local rates)
- Cooling and infrastructure: $20-$100/month
- Maintenance and upgrades: $100-$500/year
Break-even Analysis: For organizations spending more than $500/month on cloud API services, local LLM deployment typically achieves break-even within 6-12 months, depending on the hardware configuration and usage patterns.
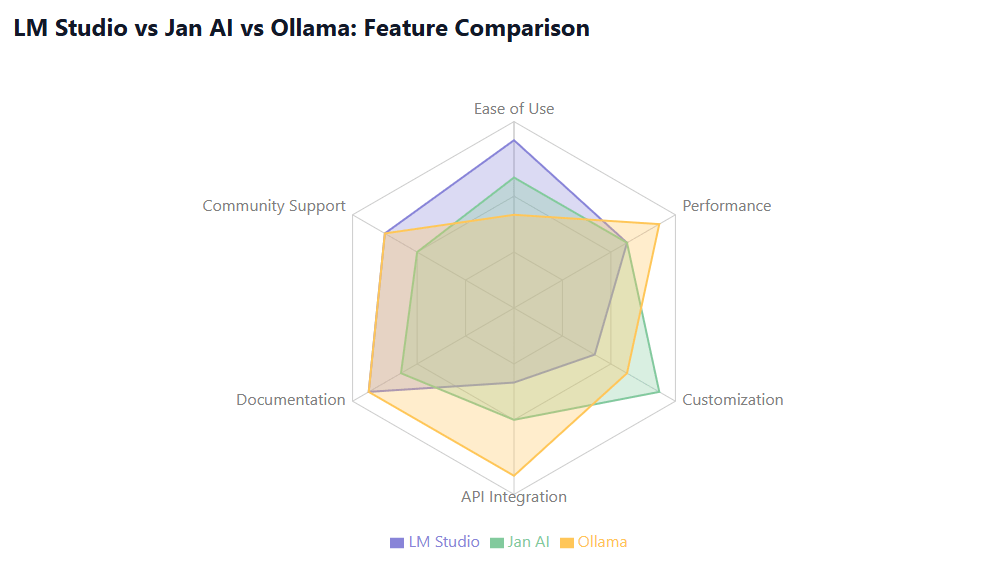
LM Studio vs Jan AI vs Ollama: Comprehensive Comparison
The choice of deployment platform significantly impacts your local LLM experience. Let’s examine the three leading platforms: LM Studio vs Jan AI and Ollama vs Jan AI, analyzing their strengths, limitations, and optimal use cases.
LM Studio: User-Friendly Interface
LM Studio has established itself as the go-to solution for users seeking a polished, graphical interface for local LLM deployment.
Strengths:
- Intuitive GUI with drag-and-drop model installation
- Comprehensive model library with one-click downloads
- Built-in chat interface for immediate testing
- Advanced configuration options for fine-tuning
- Excellent documentation and community support
Limitations:
- Primarily focused on chat interactions
- Limited API integration options
- Resource-intensive interface
Best for: Developers new to local LLMs, rapid prototyping, non-technical users requiring LLM access
Performance Metrics:
- Model loading time: Fast (30-60 seconds for 7B models)
- Memory efficiency: Good (optimized quantization)
- Ease of use: Excellent (graphical interface)
Jan AI: Open-Source Flexibility
Jan AI positions itself as a privacy-focused, open-source alternative with emphasis on local processing and user control.
Strengths:
- Fully open-source with transparent development
- Strong privacy focus with offline capabilities
- Customizable interface and workflows
- Active development community
- Cross-platform compatibility
Limitations:
- Steeper learning curve for beginners
- Limited pre-built integrations
- Occasional stability issues with updates
Best for: Privacy-conscious organizations, developers requiring customization, open-source enthusiasts
Performance Metrics:
- Model loading time: Moderate (45-90 seconds for 7B models)
- Memory efficiency: Good (efficient memory management)
- Customization: Excellent (highly configurable)
Ollama: Developer-Centric Command Line
Ollama caters to developers who prefer command-line tools and programmatic integration.
Strengths:
- Lightweight command-line interface
- Excellent API integration capabilities
- Fast model switching and management
- Docker integration for containerized deployment
- Efficient resource utilization
Limitations:
- No graphical interface (command-line only)
- Requires technical expertise
- Limited built-in chat features
Best for: Experienced developers, API integrations, automated workflows, production deployments
Performance Metrics:
- Model loading time: Excellent (15-30 seconds for 7B models)
- Memory efficiency: Excellent (minimal overhead)
- Integration: Excellent (REST API, Docker support)
Detailed Comparison Matrix
| Feature | LM Studio | Jan AI | Ollama |
|---|---|---|---|
| User Interface | Graphical (Excellent) | Graphical (Good) | Command-line (Basic) |
| Model Management | Drag & drop | Built-in browser | CLI commands |
| API Integration | Limited | Moderate | Excellent |
| Resource Usage | High | Moderate | Low |
| Learning Curve | Easy | Moderate | Steep |
| Customization | Limited | High | Moderate |
| Community Support | Large | Growing | Large |
| Documentation | Excellent | Good | Excellent |
Setup and Optimization Guides
Proper setup and optimization are crucial for maximizing the performance of your best local llm deployment. Here are comprehensive guides for each major platform.
LM Studio Setup Guide
Step 1: System Preparation
- Verify GPU compatibility (CUDA-capable NVIDIA GPU recommended)
- Install latest NVIDIA drivers (version 526.98 or newer)
- Ensure adequate system RAM (16GB minimum, 32GB recommended)
- Free up storage space (50GB+ for model files)
Step 2: Installation
- Download LM Studio from the official website
- Run the installer with administrator privileges
- Complete the initial configuration wizard
- Configure GPU acceleration settings
Step 3: Model Installation
- Browse the integrated model library
- Select appropriate model size for your hardware
- Download with automatic quantization selection
- Verify model loading and functionality
Step 4: Optimization
- Enable GPU acceleration for supported models
- Adjust context window size based on available memory
- Configure batch processing for improved throughput
- Set up automated model updates
Jan AI Setup Guide
Step 1: Environment Setup
- Install Node.js (version 18 or newer)
- Configure development environment
- Install required dependencies
- Set up local development server
Step 2: Installation Process
- Clone the Jan AI repository from GitHub
- Install dependencies using package manager
- Build the application from source
- Configure initial settings and preferences
Step 3: Model Configuration
- Download compatible model files
- Configure model paths and settings
- Set up quantization preferences
- Test model loading and inference
Step 4: Customization
- Modify interface elements for your workflow
- Configure privacy and security settings
- Set up automated backup procedures
- Integrate with existing development tools
Ollama Setup Guide
Step 1: Installation
- Install Ollama using package manager or direct download
- Verify installation with
ollama --version - Start the Ollama service
- Configure system PATH if necessary
Step 2: Model Management
# List available models
ollama list
# Pull a specific model
ollama pull llama2:7b
# Run a model
ollama run llama2:7b
# Remove a model
ollama rm llama2:7b
Step 3: API Integration
- Configure REST API endpoint
- Set up authentication if required
- Test API connectivity
- Implement error handling and retry logic
Step 4: Production Optimization
- Configure Docker containerization
- Set up load balancing for multiple instances
- Implement monitoring and logging
- Configure automatic scaling policies
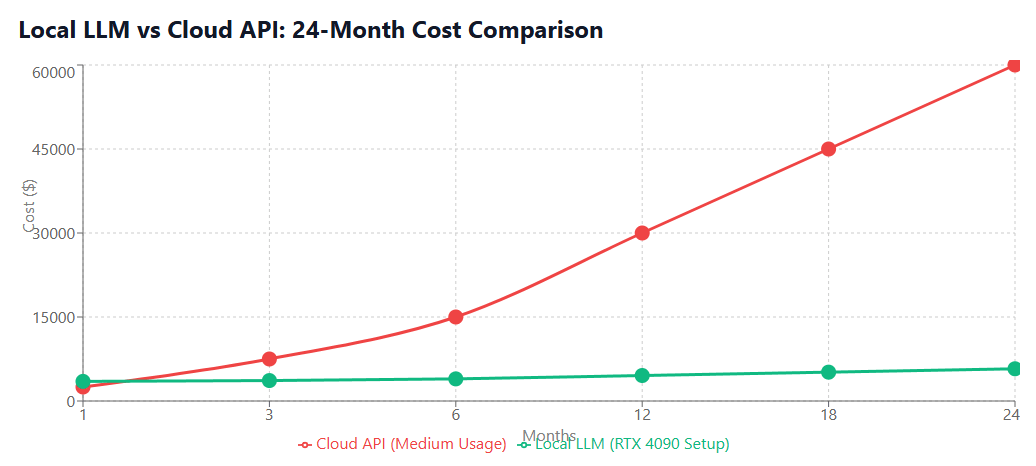
Cost Savings Analysis: Local vs Cloud APIs
Understanding the financial implications of best local llm deployment versus cloud APIs is essential for making informed decisions about your AI development infrastructure. This analysis provides a comprehensive framework for evaluating costs across different usage scenarios.
Cloud API Pricing Models
GPT-4 Pricing (2025):
- Input tokens: $0.03 per 1K tokens
- Output tokens: $0.06 per 1K tokens
- Average cost per request: $0.10-$0.50
Claude-3 Pricing:
- Input tokens: $0.015 per 1K tokens
- Output tokens: $0.075 per 1K tokens
- Average cost per request: $0.08-$0.40
Google Gemini Pricing:
- Input tokens: $0.0125 per 1K tokens
- Output tokens: $0.0375 per 1K tokens
- Average cost per request: $0.06-$0.30
Local LLM Cost Structure
Hardware Investment (One-time):
- Entry-level setup (RTX 4060 Ti): $1,500-$2,000
- Mid-range setup (RTX 4090): $2,500-$3,500
- High-end setup (A6000): $5,000-$7,000
Operational Costs (Monthly):
- Electricity (24/7 operation): $50-$150
- Cooling and infrastructure: $20-$50
- Maintenance and support: $25-$100
Break-even Analysis by Usage Patterns
Low Usage Scenario (1,000 requests/month):
- Cloud API cost: $100-$500/month
- Local LLM payback period: 12-36 months
- Recommendation: Cloud APIs for flexibility
Medium Usage Scenario (10,000 requests/month):
- Cloud API cost: $1,000-$5,000/month
- Local LLM payback period: 3-12 months
- Recommendation: Local LLMs for cost optimization
High Usage Scenario (100,000+ requests/month):
- Cloud API cost: $10,000-$50,000/month
- Local LLM payback period: 1-6 months
- Recommendation: Local LLMs with enterprise hardware
ROI Calculation Framework
Total Cost of Ownership (TCO) = Initial Hardware Cost + (Monthly Operational Costs × Months of Operation)
Cloud API Total Cost = Monthly Usage Cost × Months of Operation
Break-even Point = Initial Hardware Cost ÷ (Monthly Cloud API Cost - Monthly Operational Cost)
ROI % = [(Cloud API Annual Cost - Local LLM Annual TCO) ÷ Local LLM Annual TCO] × 100
Hidden Costs and Considerations
Cloud API Hidden Costs:
- Rate limiting fees during peak usage
- Data transfer and storage costs
- Premium support and SLA costs
- Integration and development overhead
Local LLM Hidden Costs:
- Hardware depreciation (20-30% annually)
- Upgrade and maintenance costs
- Staff training and expertise development
- Backup and disaster recovery infrastructure
Best Practices for Local LLM Deployment
Successful deployment of best local llms requires adherence to proven best practices that ensure optimal performance, security, and maintainability. These practices have been refined through extensive real-world deployments and community feedback.
Infrastructure Optimization
Hardware Configuration:
- Implement proper cooling solutions to maintain consistent performance
- Use enterprise-grade storage for model files and data persistence
- Configure redundant power supplies for critical deployments
- Implement network optimization for multi-GPU configurations
Memory Management:
- Allocate sufficient system RAM to prevent swapping
- Implement memory monitoring and alerting
- Use memory mapping for efficient model loading
- Configure swap space appropriately for large models
GPU Utilization:
- Monitor GPU temperature and utilization continuously
- Implement dynamic scaling based on demand
- Use GPU pooling for multiple concurrent requests
- Configure proper CUDA memory allocation
Security and Privacy
Access Control:
- Implement role-based access control (RBAC)
- Use API keys and authentication tokens
- Configure network firewall rules
- Monitor access patterns and usage
Data Protection:
- Encrypt model files and sensitive data at rest
- Implement secure communication channels
- Regular security audits and vulnerability assessments
- Data retention and disposal policies
Performance Monitoring
Key Metrics to Track:
- Inference latency and throughput
- GPU utilization and memory usage
- Model accuracy and quality metrics
- System resource consumption
Monitoring Tools:
- NVIDIA System Management Interface (nvidia-smi)
- Custom monitoring dashboards
- Log aggregation and analysis
- Automated alerting systems
Integration with Development Workflows
Modern AI development requires seamless integration between ai development tools and local LLM deployments. Effective integration strategies can significantly improve development productivity and deployment efficiency.
CI/CD Integration
Automated Testing:
# Example GitHub Actions workflow for LLM testing
name: LLM Integration Tests
on: [push, pull_request]
jobs:
test-llm:
runs-on: self-hosted
steps:
- uses: actions/checkout@v3
- name: Test Model Inference
run: |
ollama run llama2:7b "Write a test function"
python test_model_responses.py
Model Versioning:
- Implement semantic versioning for model updates
- Use Git LFS for large model file management
- Automated model testing and validation
- Rollback capabilities for problematic deployments
Development Environment Integration
IDE Plugins and Extensions:
- VS Code extensions for local LLM integration
- IntelliJ IDEA plugins for code generation
- Vim/Neovim configurations for terminal users
- Custom integrations for specialized workflows
API Integration Patterns:
# Example Python integration with local LLM
import requests
import json
class LocalLLMClient:
def __init__(self, base_url="http://localhost:11434"):
self.base_url = base_url
def generate(self, prompt, model="llama2:7b"):
response = requests.post(
f"{self.base_url}/api/generate",
json={
"model": model,
"prompt": prompt,
"stream": False
}
)
return response.json()["response"]
# Usage example
client = LocalLLMClient()
result = client.generate("Explain quantum computing")
print(result)
Containerization and Orchestration
Docker Integration:
# Example Dockerfile for Ollama deployment
FROM ollama/ollama:latest
# Copy custom models
COPY models/ /models/
# Expose API port
EXPOSE 11434
# Start Ollama service
CMD ["ollama", "serve"]
Kubernetes Deployment:
- Horizontal pod autoscaling based on GPU utilization
- Persistent volume claims for model storage
- Service mesh integration for microservices
- Resource quotas and limits management
Future Trends and Considerations
The landscape of local LLM deployment continues to evolve rapidly, with several emerging trends shaping the future of best local llm implementations. Understanding these trends is crucial for making strategic decisions about your AI development infrastructure.
Emerging Model Architectures
Mixture of Experts (MoE) Models: The increasing adoption of MoE architectures allows for larger, more capable models while maintaining reasonable inference costs. Models like Mixtral 8x7B demonstrate how sparse activation patterns can deliver exceptional performance with modest hardware requirements.
Multimodal Integration: Future local LLMs will increasingly support multimodal capabilities, processing text, images, audio, and video within unified frameworks. This trend aligns with the growing demand for comprehensive AI solutions that can handle diverse data types.
Edge-Optimized Models: The development of models specifically optimized for edge deployment will continue, focusing on efficiency and performance in resource-constrained environments.
Hardware Evolution
Specialized AI Chips:
- Apple’s M-series chips with unified memory architecture
- Intel’s discrete GPU offerings for AI workloads
- AMD’s RDNA3 architecture improvements
- Dedicated AI inference chips from various manufacturers
Memory Architecture Improvements:
- High-bandwidth memory (HBM) becoming more accessible
- Unified memory architectures reducing GPU-CPU transfer overhead
- Non-volatile memory express (NVMe) improvements for model loading
Regulatory and Compliance Considerations
Data Sovereignty: Increasing regulatory requirements for data localization make local LLM deployment more attractive for compliance-focused organizations.
AI Governance:
- Emerging regulations around AI model deployment and usage
- Requirements for model transparency and explainability
- Audit trails and compliance reporting capabilities
Integration with Existing Infrastructure
Hybrid Cloud Architectures: Organizations are increasingly adopting hybrid approaches that combine local LLM deployment with selective cloud API usage for specialized tasks.
Integration with Existing DevOps:
- Seamless integration with existing monitoring and alerting systems
- Compatibility with established deployment pipelines
- Integration with existing identity and access management systems
The future of local LLM deployment will be characterized by increased efficiency, broader hardware compatibility, and deeper integration with existing development workflows. Organizations that invest in local LLM capabilities now will be well-positioned to take advantage of these emerging trends while maintaining cost-effective and privacy-conscious AI development practices.
Conclusion
The adoption of best local llms represents a transformative shift in AI development strategy, offering organizations unprecedented control over their artificial intelligence infrastructure while delivering significant cost savings and enhanced privacy protection. Throughout this comprehensive analysis, we’ve explored the compelling advantages of local LLM deployment, from predictable cost structures to complete data sovereignty.
The comparison between lm studio vs jan ai and ollama vs jan ai reveals distinct strengths for different use cases, with LM Studio excelling in user-friendly deployment, Jan AI providing open-source flexibility, and Ollama delivering developer-centric command-line efficiency. Each platform serves specific organizational needs, and the choice ultimately depends on technical requirements, team expertise, and integration preferences.
Our cost analysis demonstrates that organizations processing more than 10,000 requests monthly can achieve significant ROI within 3-12 months of local LLM deployment. The break-even calculations clearly favor local deployment for high-volume use cases, while the operational benefits extend far beyond mere cost savings to include improved latency, customization capabilities, and regulatory compliance.
The hardware landscape for local LLM deployment has matured considerably, with options ranging from consumer-grade solutions suitable for development and prototyping to enterprise configurations capable of supporting production workloads. The democratization of powerful AI capabilities through accessible hardware represents a fundamental shift in how organizations approach AI development.
As we look toward the future, emerging trends in model architectures, hardware evolution, and regulatory requirements will continue to strengthen the case for local LLM deployment. Organizations that establish local AI capabilities now will be well-positioned to leverage future innovations while maintaining cost-effective operations.
For businesses seeking to optimize their AI development costs while maintaining complete control over their data and infrastructure, local LLMs offer a compelling solution that aligns with modern requirements for cloud cost optimization and scalable cloud computing. The integration of these solutions with comprehensive SaaS management platforms creates a powerful foundation for sustainable AI development.
The journey toward local LLM deployment requires careful planning, appropriate hardware investment, and ongoing optimization. However, the benefits—including cost predictability, enhanced privacy, improved performance, and strategic independence—make this investment increasingly attractive for organizations serious about their AI development future.
By implementing the best practices, optimization strategies, and integration approaches outlined in this guide, organizations can successfully deploy best local llm models that deliver exceptional value while supporting their broader digital transformation objectives. The future of AI development is local, and the time to begin that journey is now.