
The artificial intelligence landscape has fundamentally transformed how organizations approach machine learning and natural language processing capabilities. As businesses increasingly integrate large language models (LLMs) into their operations, a critical decision emerges: should they adopt LLM as a Service (LLMaaS) solutions or invest in self-hosted AI infrastructure?
This comprehensive analysis examines the cost and performance implications of both approaches, providing organizations with the insights needed to make informed decisions about their AI deployment strategies. Similar to how cloud management strategies have evolved to address complex infrastructure needs, AI deployment requires careful consideration of multiple factors including costs, performance, scalability, and operational complexity.
The choice between LLMaaS and self-hosted solutions mirrors broader technology decisions organizations face when evaluating SaaS solutions versus on-premises infrastructure. Understanding these trade-offs is essential for optimizing both AI capabilities and organizational resources while maintaining competitive advantages in an increasingly AI-driven marketplace.
What is LLM as a Service?
LLM as a Service (LLMaaS) represents a cloud-based delivery model where organizations access pre-trained large language models through APIs and web interfaces without managing the underlying infrastructure. This approach parallels traditional SaaS solutions by abstracting complex technical requirements while providing scalable access to advanced AI capabilities.
LLMaaS platforms typically offer several key characteristics that distinguish them from self-hosted alternatives. First, they provide instant access to state-of-the-art models without requiring extensive setup or configuration. Organizations can integrate these services into their applications through standardized APIs, enabling rapid deployment and testing of AI functionalities.
The service model includes automatic updates and improvements to underlying models, ensuring users always access the latest AI capabilities without manual intervention. This approach eliminates the need for organizations to maintain expertise in model training, fine-tuning, or infrastructure management, allowing teams to focus on application development and business value creation.
Payment structures for LLMaaS typically follow usage-based pricing models, charging organizations based on API calls, tokens processed, or computational resources consumed. This pricing approach provides cost predictability and aligns expenses with actual utilization, making it easier for organizations to budget and scale their AI initiatives.
Popular LLMaaS providers include OpenAI’s GPT models, Google’s PaLM API, Anthropic’s Claude, and Microsoft’s Azure OpenAI Service. These platforms offer varying capabilities, pricing structures, and integration options, allowing organizations to select services that best align with their specific requirements and use cases.
Understanding Self-Hosted LLM Infrastructure
Self-hosted LLM infrastructure involves organizations deploying and managing large language models on their own computational resources, whether on-premises or in private cloud environments. This approach provides complete control over the AI pipeline, from model selection and customization to data handling and performance optimization.
The self-hosted model requires significant upfront investment in hardware infrastructure, including high-performance GPUs, substantial memory capacity, and robust networking capabilities. Organizations must also invest in specialized expertise, including machine learning engineers, DevOps professionals, and infrastructure specialists capable of managing complex AI workloads.
Implementation complexity varies depending on the chosen approach. Organizations may opt to deploy existing open-source models like Llama, Falcon, or Mistral, which reduces development time but still requires significant infrastructure and operational expertise. Alternatively, some organizations choose to train custom models, which dramatically increases complexity and resource requirements but provides maximum customization and competitive differentiation.
Self-hosted deployments offer several advantages over service-based approaches. Organizations maintain complete data sovereignty, ensuring sensitive information never leaves their controlled environment. They can customize models for specific use cases, implement proprietary training techniques, and optimize performance for particular workloads or industries.
However, self-hosted approaches also introduce operational challenges. Organizations must handle model updates, security patching, monitoring, and troubleshooting without vendor support. They bear responsibility for ensuring high availability, implementing disaster recovery procedures, and managing capacity planning as AI workloads scale.
Cost Analysis: LLMaaS vs. Self-Hosted
Understanding the total cost of ownership (TCO) for both LLMaaS and self-hosted approaches requires examining multiple cost components beyond initial deployment expenses. This analysis reveals significant differences in cost structures, predictability, and long-term financial implications.
LLMaaS Cost Structure
LLMaaS platforms typically employ usage-based pricing models that charge organizations based on actual consumption. Common pricing metrics include per-token charges, API call volumes, or computational time consumed. This approach provides cost transparency and allows organizations to scale expenses with utilization patterns.
For example, OpenAI’s GPT-4 pricing structure charges approximately $0.03 per 1,000 input tokens and $0.06 per 1,000 output tokens. Organizations processing 1 million tokens monthly would incur costs around $90, making it accessible for small to medium-scale deployments. However, costs can escalate rapidly for high-volume applications or enterprise-scale implementations.
Additional LLMaaS costs may include premium support subscriptions, enhanced security features, or dedicated capacity reservations. Some providers offer volume discounts or enterprise agreements that reduce per-unit costs for large-scale deployments, but these benefits typically require significant commitment levels.
The predictability of LLMaaS costs depends heavily on usage patterns. Organizations with consistent, predictable AI workloads can accurately forecast expenses, while those with variable or seasonal usage may experience significant cost fluctuations. This variability can complicate budgeting processes and require careful monitoring to avoid unexpected expenses.
Self-Hosted Infrastructure Costs
Self-hosted LLM deployments involve substantial upfront capital expenditures for hardware acquisition, software licensing, and infrastructure setup. High-end GPU configurations suitable for large model inference can cost $100,000 to $500,000 or more, depending on performance requirements and redundancy needs.
Operational expenses for self-hosted deployments include electricity consumption, which can be substantial given the power requirements of GPU-intensive workloads. Data center costs, cooling requirements, and network infrastructure add additional ongoing expenses that organizations must factor into their TCO calculations.
Personnel costs represent another significant component of self-hosted deployments. Organizations require specialized expertise in machine learning, infrastructure management, and operations, with salaries for qualified professionals often exceeding $150,000 annually. Multiple specialists may be needed to ensure adequate coverage and expertise depth.
Maintenance and upgrade costs continue throughout the infrastructure lifecycle. Hardware refresh cycles, software updates, security patches, and model retraining requirements generate ongoing expenses that organizations must budget and plan for. These costs can be unpredictable and may require significant investments to maintain competitive AI capabilities.
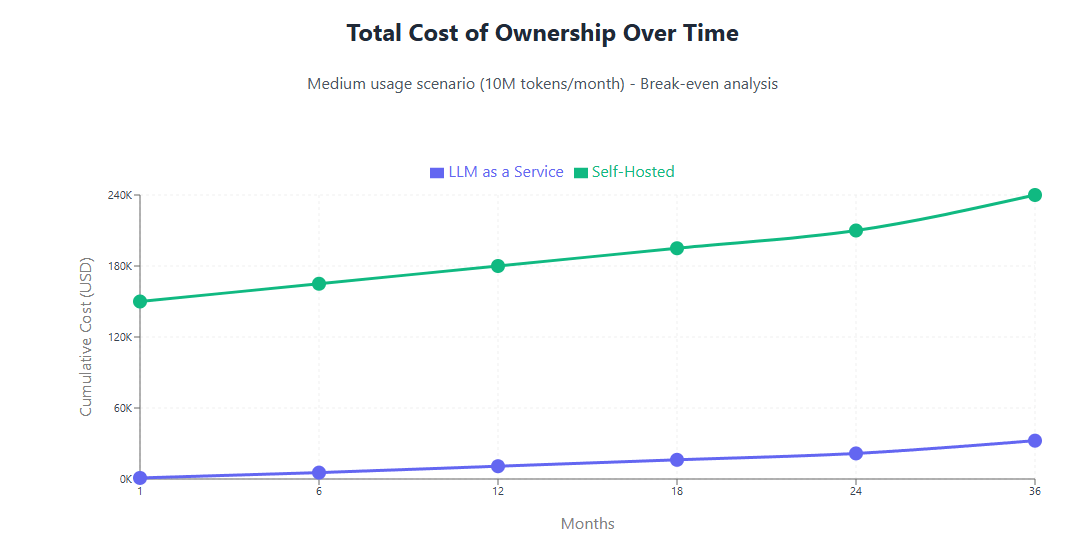
Comparative Cost Analysis
When comparing total costs between LLMaaS and self-hosted approaches, the break-even point varies significantly based on utilization levels, performance requirements, and organizational capabilities. For low to moderate usage patterns (under 10 million tokens monthly), LLMaaS typically provides superior cost efficiency due to lower upfront investment and operational complexity.
Organizations with high-volume, consistent AI workloads may find self-hosted approaches more cost-effective over time, particularly when factoring in economies of scale and depreciation benefits. However, this advantage requires sustaining utilization levels sufficient to justify infrastructure investments and operational overhead.
The analysis becomes more complex when considering indirect costs such as opportunity costs, time-to-market considerations, and risk factors. Organizations implementing self-hosted solutions may experience longer deployment timelines and higher implementation risks, potentially impacting business value creation and competitive positioning.
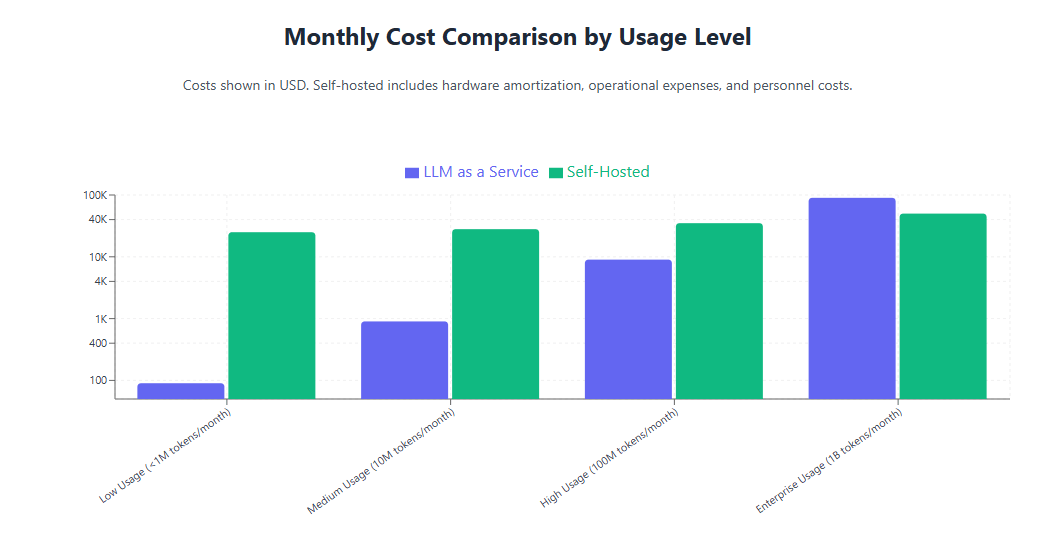
Performance Comparison Framework
Evaluating performance differences between LLMaaS and self-hosted approaches requires examining multiple dimensions including latency, throughput, reliability, and customization capabilities. These factors significantly impact user experience, application performance, and operational efficiency.
Latency and Response Time
LLMaaS platforms typically introduce network latency due to API calls over public internet connections. Round-trip times can range from 100-500 milliseconds or more, depending on geographic location, network conditions, and provider infrastructure. This latency may be acceptable for many applications but can impact real-time or interactive use cases.
Self-hosted deployments can achieve significantly lower latency by eliminating network overhead and optimizing local infrastructure. Organizations can achieve sub-100 millisecond response times or better, depending on hardware configuration and model optimization. This advantage becomes critical for applications requiring real-time responses or supporting high-frequency interactions.
However, achieving optimal performance with self-hosted solutions requires significant expertise and optimization effort. Organizations must fine-tune hardware configurations, optimize model serving infrastructure, and implement efficient caching strategies to realize performance benefits. Without proper optimization, self-hosted deployments may actually perform worse than well-optimized LLMaaS platforms.
Throughput and Scalability
LLMaaS platforms offer virtually unlimited scalability, automatically handling traffic spikes and scaling resources based on demand. Providers manage load balancing, resource allocation, and capacity planning, ensuring consistent performance even during peak usage periods. This scalability comes without additional infrastructure investment or operational complexity for end users.
Self-hosted deployments face throughput limitations based on available hardware resources. Organizations must carefully plan capacity to handle peak loads, often requiring over-provisioning to ensure adequate performance during high-demand periods. This approach can be cost-inefficient but provides predictable performance characteristics.
Scaling self-hosted infrastructure requires significant planning, investment, and operational complexity. Organizations must purchase additional hardware, configure load balancing, and implement monitoring systems to manage increased capacity. This process can take weeks or months, limiting organizational agility and responsiveness to changing business needs.
Reliability and Availability
Leading LLMaaS providers offer enterprise-grade reliability with service level agreements (SLAs) guaranteeing 99.9% or higher uptime. These platforms implement redundancy, automatic failover, and disaster recovery capabilities that would be difficult and expensive for individual organizations to replicate.
Self-hosted deployments require organizations to implement their own reliability and availability measures. This includes redundant hardware, backup systems, monitoring infrastructure, and operational procedures to handle failures and maintenance activities. Achieving high availability can be complex and expensive, particularly for smaller organizations.
The risk profile differs significantly between approaches. LLMaaS users depend on provider reliability but benefit from professional management and support. Self-hosted deployments provide more control but require organizations to assume full responsibility for availability, security, and disaster recovery planning.
Scalability and Resource Management
Effective scalability planning differs substantially between LLMaaS and self-hosted approaches, with significant implications for cost management, performance optimization, and operational efficiency. Understanding these differences helps organizations align their AI infrastructure choices with business growth patterns and resource constraints.
Dynamic Resource Allocation
LLMaaS platforms excel in dynamic resource allocation, automatically adjusting computational resources based on real-time demand. This elasticity eliminates the need for capacity planning and ensures optimal resource utilization without requiring organizational intervention. During peak usage periods, providers automatically allocate additional resources, while scaling down during low-demand periods to optimize costs.
This dynamic allocation model particularly benefits organizations with variable or unpredictable AI workloads. Seasonal businesses, applications with viral growth potential, or use cases with irregular usage patterns can leverage LLMaaS platforms without worrying about infrastructure constraints or unused capacity costs.
Self-hosted deployments require manual capacity planning and resource provisioning. Organizations must anticipate peak demand, purchase appropriate hardware, and configure systems to handle maximum expected loads. This approach often results in over-provisioning during normal operations but may still face capacity constraints during unexpected demand spikes.
Geographic Distribution and Edge Computing
Many LLMaaS providers offer global infrastructure with multiple data centers and edge computing capabilities. This distribution can improve performance for geographically dispersed user bases while maintaining consistent service quality. Providers handle complex logistics of data replication, load balancing, and regional optimization.
Organizations implementing self-hosted solutions must independently address geographic distribution requirements. This may involve deploying infrastructure across multiple locations, implementing data replication strategies, and managing network connectivity between sites. Such complexity significantly increases implementation costs and operational overhead.
The emerging trend toward edge computing integration affects both deployment models. LLMaaS providers are increasingly offering edge computing capabilities, bringing AI processing closer to end users. Self-hosted organizations must evaluate edge deployment strategies independently, potentially requiring distributed infrastructure management capabilities.
Resource Optimization Strategies
Effective resource optimization requires different approaches for LLMaaS and self-hosted deployments. LLMaaS users can optimize costs through usage pattern analysis, API call efficiency, and intelligent caching strategies. Understanding provider pricing models enables organizations to structure applications for cost-effective operation.
Organizations should implement monitoring and analytics tools to track API usage patterns, identify optimization opportunities, and detect cost anomalies. Similar to cloud cost optimization strategies, LLMaaS cost management requires ongoing attention and systematic optimization efforts.
Self-hosted resource optimization involves hardware utilization monitoring, model serving efficiency, and infrastructure optimization. Organizations can achieve significant cost savings through GPU utilization optimization, batch processing strategies, and intelligent workload scheduling. However, these optimizations require specialized expertise and ongoing attention.
Security and Compliance Considerations
Security and compliance requirements significantly influence the choice between LLMaaS and self-hosted AI deployments. Organizations in regulated industries or those handling sensitive data must carefully evaluate how each approach addresses their specific security and compliance obligations.
Data Sovereignty and Privacy
Self-hosted deployments provide complete data sovereignty, ensuring sensitive information never leaves organizational control. This approach is particularly important for organizations handling personally identifiable information (PII), financial data, or proprietary business intelligence. Complete data control enables organizations to implement customized security measures and maintain audit trails without dependency on external providers.
LLMaaS platforms require organizations to transmit data to external providers for processing, raising potential privacy and sovereignty concerns. However, leading providers implement robust security measures including encryption in transit and at rest, data isolation, and compliance certifications that address many organizational requirements.
Some LLMaaS providers offer specialized deployment options for security-sensitive organizations, including private instances, dedicated capacity, and enhanced security features. These options provide middle-ground solutions that balance security requirements with operational simplicity, though typically at higher cost points.
Regulatory Compliance
Organizations in regulated industries must ensure their AI deployments comply with relevant regulations such as GDPR, HIPAA, SOX, or industry-specific requirements. Self-hosted deployments provide maximum control over compliance implementation but require organizations to independently address all regulatory requirements.
Many LLMaaS providers maintain compliance certifications and offer features specifically designed to support regulatory requirements. These may include data residency options, audit logging, access controls, and deletion capabilities that help organizations meet their compliance obligations while leveraging external AI services.
The compliance landscape for AI systems continues to evolve, with new regulations and requirements emerging regularly. Organizations must consider how their chosen deployment approach will adapt to changing regulatory environments and whether their selected approach provides sufficient flexibility to address future requirements.
Security Implementation and Management
Self-hosted security implementation requires organizations to address all aspects of AI system security, from network security and access controls to model security and data protection. This comprehensive responsibility provides maximum control but requires significant expertise and ongoing attention to security best practices.
LLMaaS providers implement professional-grade security measures that many organizations would find difficult or expensive to replicate independently. These include advanced threat detection, regular security auditing, and specialized security expertise dedicated to AI system protection.
Organizations must evaluate their internal security capabilities and risk tolerance when choosing between deployment approaches. Those with limited security expertise may benefit from leveraging provider security capabilities, while organizations with advanced security requirements may prefer the control provided by self-hosted deployments.
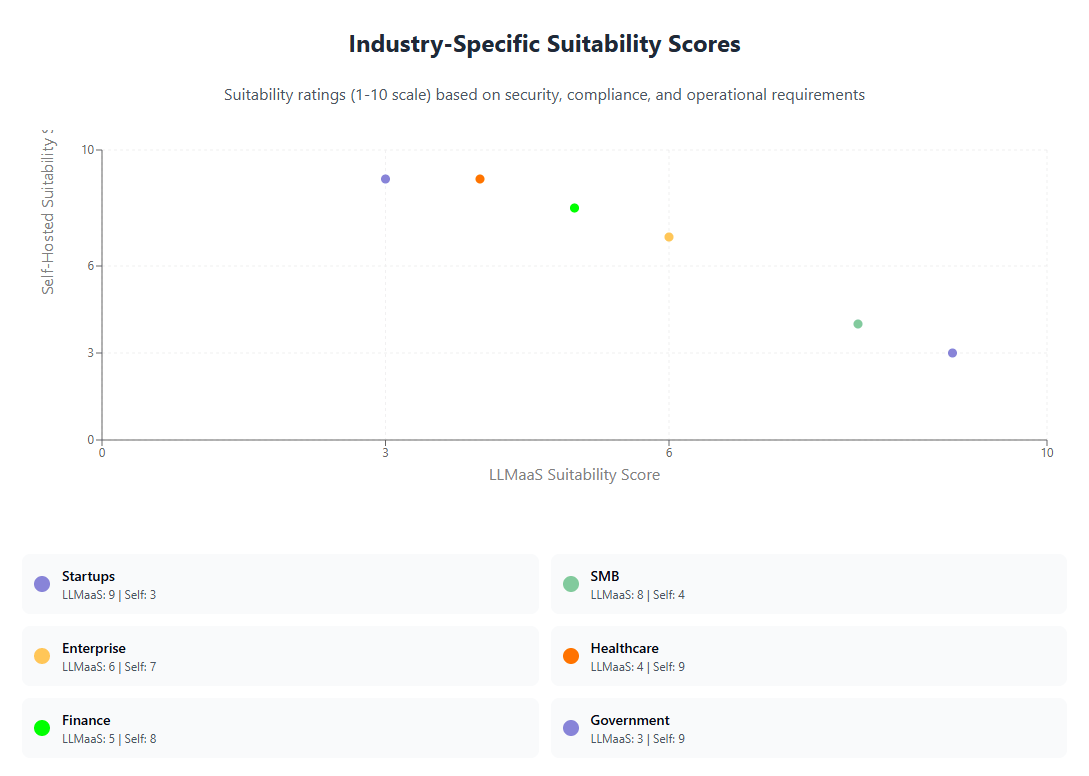
Implementation Strategies and Best Practices
Successful implementation of either LLMaaS or self-hosted AI solutions requires careful planning, strategic execution, and ongoing optimization. Organizations should develop comprehensive implementation strategies that address technical, operational, and business considerations while maintaining flexibility to adapt to changing requirements.
Hybrid Deployment Approaches
Many organizations find optimal value through hybrid approaches that combine LLMaaS and self-hosted capabilities based on specific use case requirements. This strategy allows organizations to leverage the benefits of both approaches while mitigating their respective limitations.
For example, organizations might use LLMaaS platforms for development, testing, and low-security applications while implementing self-hosted solutions for production workloads involving sensitive data or requiring maximum performance. This approach provides flexibility while optimizing costs and security considerations.
Hybrid deployments require careful architecture planning to ensure seamless integration between different AI platforms. Organizations must develop consistent APIs, data handling procedures, and monitoring capabilities that work across both deployment models. This complexity requires additional technical expertise but can provide significant strategic advantages.
Gradual Migration Strategies
Organizations transitioning between deployment models should consider gradual migration approaches that minimize risk and allow for learning and optimization. Starting with LLMaaS platforms for initial AI adoption can provide valuable experience and insights that inform future infrastructure decisions.
As organizations develop AI expertise and usage patterns become more predictable, they may choose to migrate certain workloads to self-hosted infrastructure while maintaining LLMaaS platforms for other use cases. This gradual approach allows organizations to optimize costs and performance over time while building internal capabilities.
Migration planning should include comprehensive cost analysis, performance testing, and risk assessment. Organizations should establish clear success criteria and rollback procedures to ensure smooth transitions and minimize business impact during migration processes.
Vendor Selection and Management
Choosing appropriate LLMaaS providers requires careful evaluation of multiple factors including pricing models, performance characteristics, security features, and long-term viability. Organizations should avoid vendor lock-in by maintaining compatibility with multiple providers or implementing abstraction layers that enable provider switching.
Effective vendor management includes establishing clear service level agreements, monitoring performance metrics, and maintaining alternative options in case of service disruptions or strategic changes. Organizations should treat LLMaaS providers as critical business partners and implement appropriate governance and oversight procedures.
For self-hosted deployments, vendor selection focuses on hardware providers, software platforms, and support services. Organizations should evaluate total cost of ownership, technical support quality, and long-term product roadmaps when making infrastructure investment decisions.
Market Trends and Future Outlook
The AI infrastructure market continues to evolve rapidly, with new technologies, business models, and competitive dynamics emerging regularly. Understanding current trends and future directions helps organizations make informed decisions about their AI deployment strategies and avoid obsolete approaches.
Emerging AI Infrastructure Technologies
Edge AI computing represents a significant trend that affects both LLMaaS and self-hosted deployment strategies. As AI processing capabilities move closer to end users and data sources, organizations must consider how their chosen deployment approach will adapt to distributed computing requirements.
Specialized AI hardware, including purpose-built inference chips and neuromorphic processors, may significantly impact the economics of self-hosted deployments. These technologies promise improved performance and energy efficiency, potentially making self-hosted solutions more attractive for specific use cases.
Quantum computing developments, while still experimental, may eventually revolutionize AI processing capabilities. Organizations should monitor quantum computing progress and consider how their current infrastructure choices position them for future technology adoption.
Business Model Evolution
The LLMaaS market is experiencing rapid evolution with new pricing models, service offerings, and competitive dynamics. Subscription-based pricing, compute credit systems, and performance-based pricing models are emerging as alternatives to traditional usage-based pricing.
Open-source AI models continue to improve in quality and capability, potentially making self-hosted deployments more attractive by reducing model development costs and technical barriers. Organizations should monitor open-source developments and evaluate how these models might affect their AI infrastructure strategies.
Integration with Broader Technology Ecosystems
AI infrastructure decisions increasingly integrate with broader technology and business strategies. Organizations must consider how their AI deployment approach aligns with existing cloud management strategies, data management practices, and digital transformation initiatives.
The integration of AI capabilities into comprehensive business platforms and applications requires consideration of compatibility, performance, and operational requirements across entire technology ecosystems. Organizations should evaluate how their AI infrastructure choices support broader business objectives and technology strategies.
Cost Optimization Strategies for AI Infrastructure
Effective cost optimization for AI infrastructure requires systematic approaches that address both immediate expenses and long-term financial sustainability. Organizations should implement comprehensive cost management strategies regardless of their chosen deployment approach, similar to broader SaaS spend management practices.
LLMaaS Cost Optimization
Organizations using LLMaaS platforms can implement several strategies to optimize costs while maintaining performance and functionality. Usage monitoring and analytics provide insights into consumption patterns, enabling organizations to identify optimization opportunities and eliminate waste.
Implementing intelligent caching strategies can significantly reduce API calls and associated costs. Organizations should cache frequently accessed results, implement smart cache invalidation policies, and optimize cache hit ratios to minimize redundant processing costs.
Batch processing approaches can reduce costs by aggregating multiple requests into single API calls where possible. This strategy requires application architecture considerations but can provide substantial cost savings for high-volume use cases.
API call optimization involves structuring requests to minimize token usage, implementing efficient prompt engineering techniques, and using appropriate model sizes for specific tasks. Organizations should regularly review and optimize their API usage patterns to ensure cost-effective operation.
Self-Hosted Infrastructure Optimization
Self-hosted AI infrastructure optimization requires attention to both hardware utilization and operational efficiency. GPU utilization monitoring helps organizations identify underutilized resources and optimize workload scheduling to maximize hardware value.
Power management strategies can significantly impact operational costs for self-hosted deployments. Implementing dynamic power scaling, optimizing cooling systems, and selecting energy-efficient hardware configurations reduce ongoing electricity expenses.
Workload optimization involves implementing efficient model serving architectures, optimizing batch sizes, and implementing intelligent load balancing. These optimizations require technical expertise but can provide substantial performance and cost improvements.
Financial Planning and Budgeting
Comprehensive financial planning for AI infrastructure requires understanding both predictable and variable cost components. Organizations should establish budgeting frameworks that account for growth scenarios, usage variability, and technology evolution.
Cost allocation and chargeback systems help organizations understand AI infrastructure costs by department, project, or application. This visibility enables better decision-making and encourages responsible usage patterns across the organization.
Regular cost reviews and optimization assessments ensure organizations maintain cost-effective AI infrastructure over time. These reviews should evaluate both technical performance and financial efficiency, identifying opportunities for ongoing improvement.
Conclusion
The decision between LLM as a Service and self-hosted AI infrastructure represents a critical strategic choice that affects organizational costs, capabilities, and competitive positioning. This analysis demonstrates that neither approach provides universal advantages; instead, optimal decisions depend on specific organizational requirements, constraints, and objectives.
LLMaaS platforms offer compelling advantages for organizations seeking rapid AI adoption, minimal operational complexity, and scalable cost structures. These platforms excel for organizations with variable usage patterns, limited AI expertise, or requirements for rapid deployment and iteration. The subscription-based pricing models provide cost predictability and eliminate large upfront investments, making AI capabilities accessible to organizations of all sizes.
Self-hosted deployments provide advantages for organizations with consistent, high-volume AI requirements, strict security or compliance needs, or desires for maximum customization and control. While requiring significant upfront investment and operational expertise, self-hosted approaches can provide superior long-term cost efficiency for appropriate use cases while ensuring complete data sovereignty and customization capabilities.
The evolution toward hybrid deployment strategies reflects the maturation of the AI infrastructure market. Organizations increasingly recognize that optimal AI strategies may involve multiple deployment approaches optimized for different use cases, security requirements, and performance needs. This hybrid approach provides flexibility while maximizing the benefits of both deployment models.
Cost optimization remains critical regardless of deployment approach. Organizations must implement systematic monitoring, analysis, and optimization practices to ensure their AI infrastructure investments provide maximum business value. Similar to broader cloud cost optimization strategies, AI cost management requires ongoing attention and systematic improvement efforts.
Future technology developments will continue to influence the LLMaaS versus self-hosted decision landscape. Edge computing capabilities, specialized AI hardware, and evolving business models may shift the economic and performance characteristics of both approaches. Organizations should maintain flexibility and regularly reassess their AI infrastructure strategies as the technology landscape evolves.
The growing importance of AI capabilities in business competition makes infrastructure decisions increasingly strategic. Organizations that effectively align their AI deployment strategies with business objectives, cost constraints, and operational capabilities will be best positioned to leverage AI for competitive advantage while maintaining financial sustainability.
Ultimately, successful AI infrastructure implementation requires comprehensive evaluation of organizational requirements, careful planning and execution, and ongoing optimization efforts. By understanding the trade-offs, costs, and benefits of both LLMaaS and self-hosted approaches, organizations can make informed decisions that support their AI ambitions while optimizing resource allocation and operational efficiency in an increasingly AI-driven business environment.
For organizations seeking to optimize their AI and broader technology spending, platforms like Binadox provide comprehensive visibility and management capabilities that extend across both traditional SaaS solutions and emerging AI infrastructure requirements. Effective cost management becomes increasingly critical as organizations expand their AI capabilities and technology portfolios.